Extraire la racine et le nom de domaine d'une URL avec Google Sheets (+TEMPLATE) + ...+....
3 techniques pour filtrer les données Search Console sans quitter la page

Table des matières
Avant d'entrer dans le vif du sujet, je tenais à te signaler la sortie de mon outil gratuit XPATH4SEO.
C'est une base de données d'expressions XPath classées par catégorie : contenu, liens, microdonnées, balises meta, etc.
L'objectif : te faire gagner du temps dans l'extraction de données SEO en n'ayant plus qu'à copier/coller le bout de code correspondant à ton besoin. Bon scraping !
Toi aussi, parfois, tu aimerais pouvoir filtrer les données Search Console (clics, impressions, etc.) directement depuis l'interface de l'outil, sans passer par un export CSV ou Google Sheets qui te rajoute des clics superflus ?
Par exemple, pour isoler les requêtes avec beaucoup d'impressions et peu de clics ?
Alors oui, c'est vrai, il y a des filtres dans la Search Console. Le problème, c'est qu'aucun d'eux ne permet de manipuler les valeurs de clics, d'impressions, ou de position moyenne.
Du coup, comment faire ?
Et bien, je me suis penché sur la question et je te propose 3 techniques simples que tu vas pouvoir utiliser dès aujourd'hui.
1ère solution : le plugin XPath Helper
XPath Helper est une extension que j'utilise depuis pas mal d'années maintenant et qui me fait gagner un temps fou sur toutes sortes d'opérations de scraping.
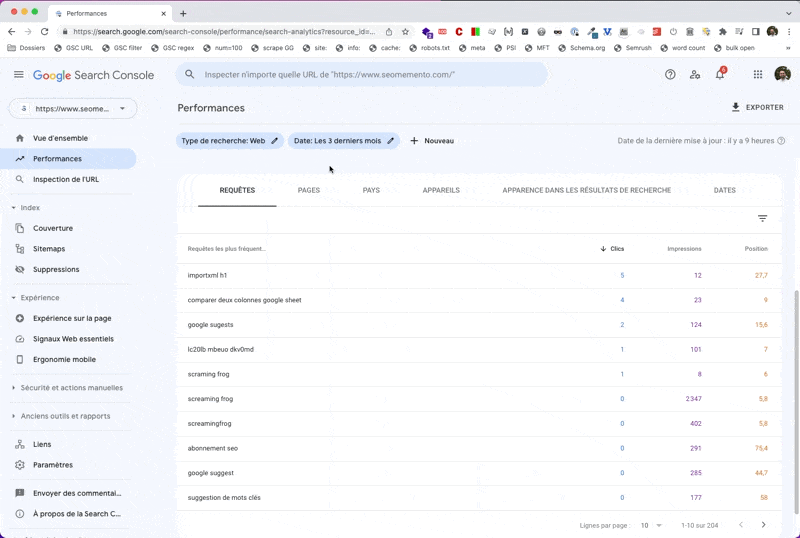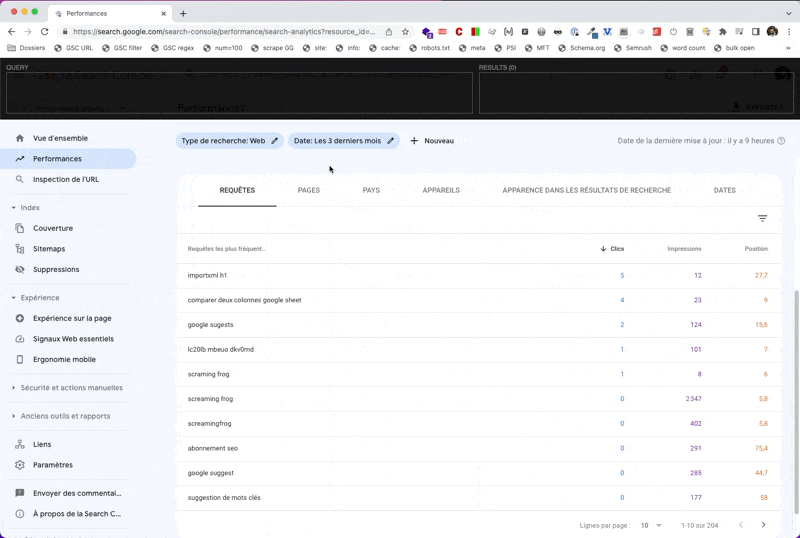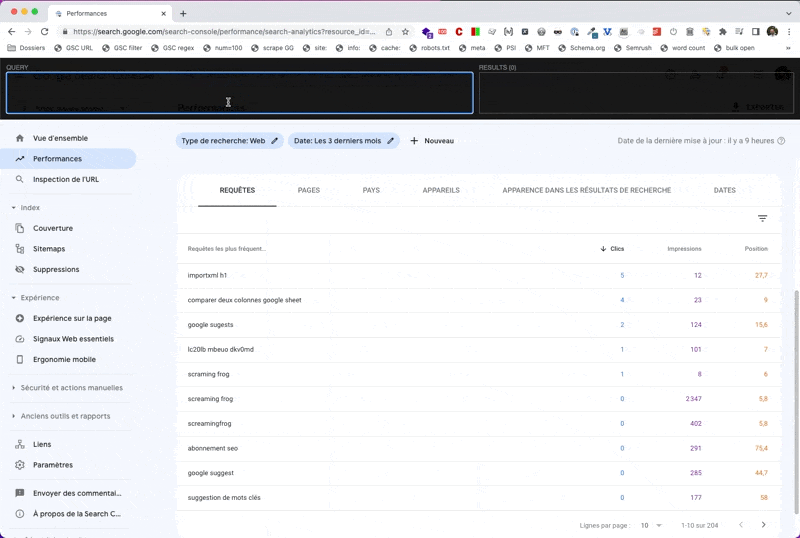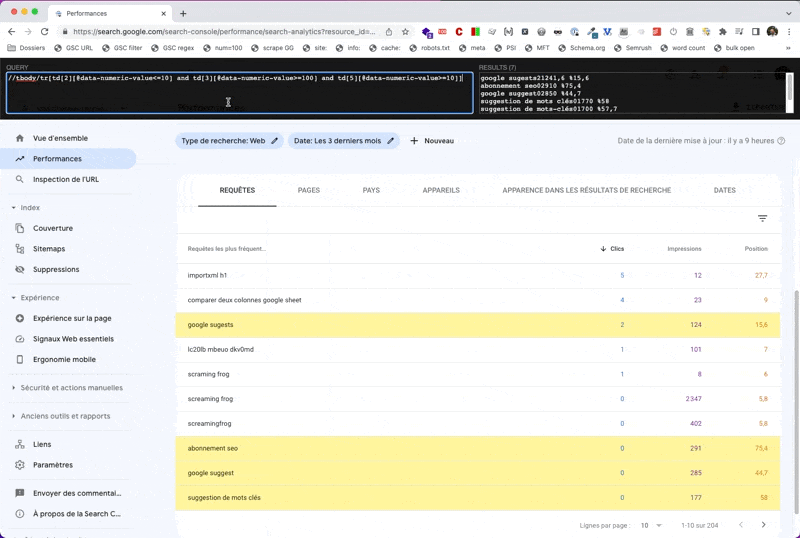
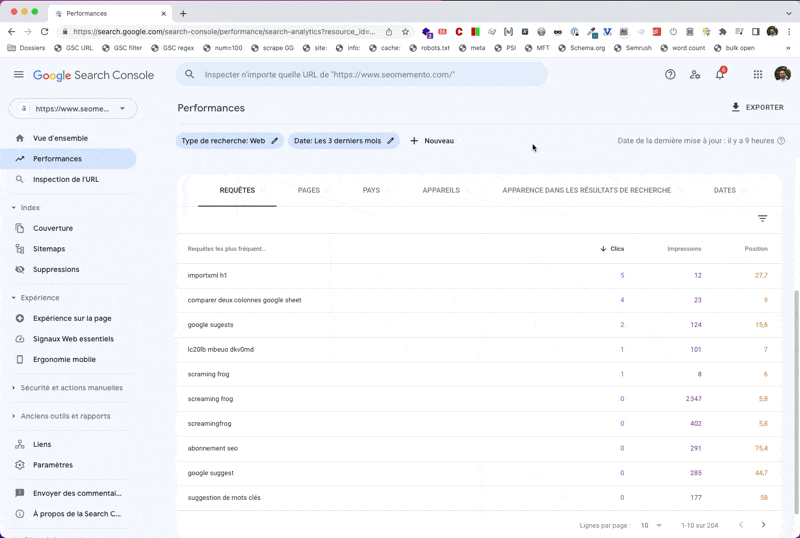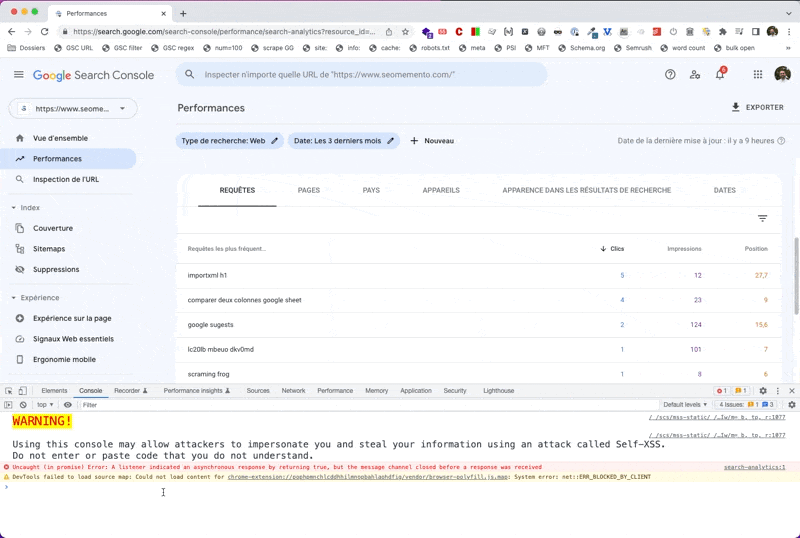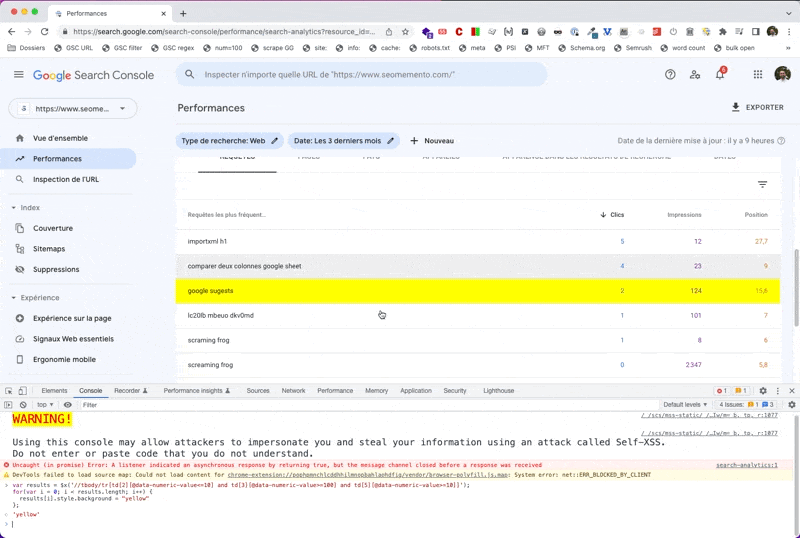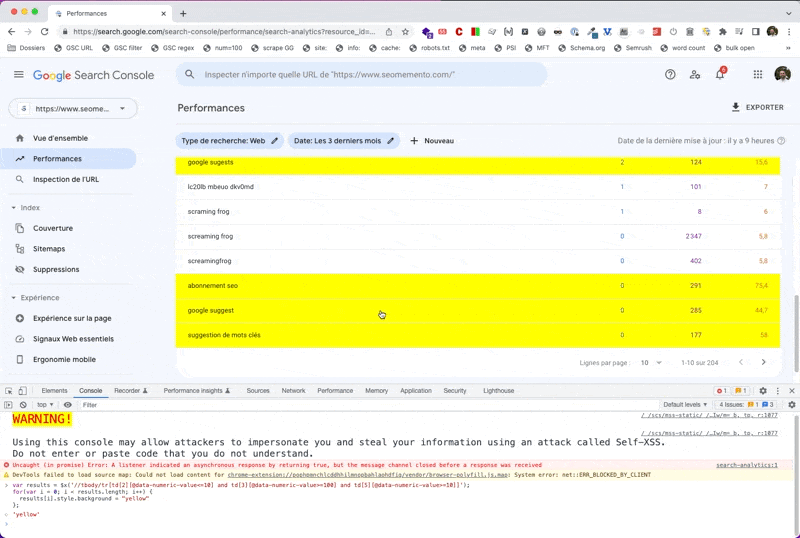
Ici, je vais l'utiliser pour surligner les données qui m'intéressent dans le rapport Search Console.
Une fois que tu as installé l'add-on, appuie sur CTRL ⇧ X pour ouvrir le layer en haut de page.
Le fonctionnement est le suivant : à gauche tu tapes ta requête XPath, à droite tu récupères les résultats. Et en bonus, ce que tu sélectionnes avec XPath apparaît en fond jaune dans la page.
Pratique, non ?
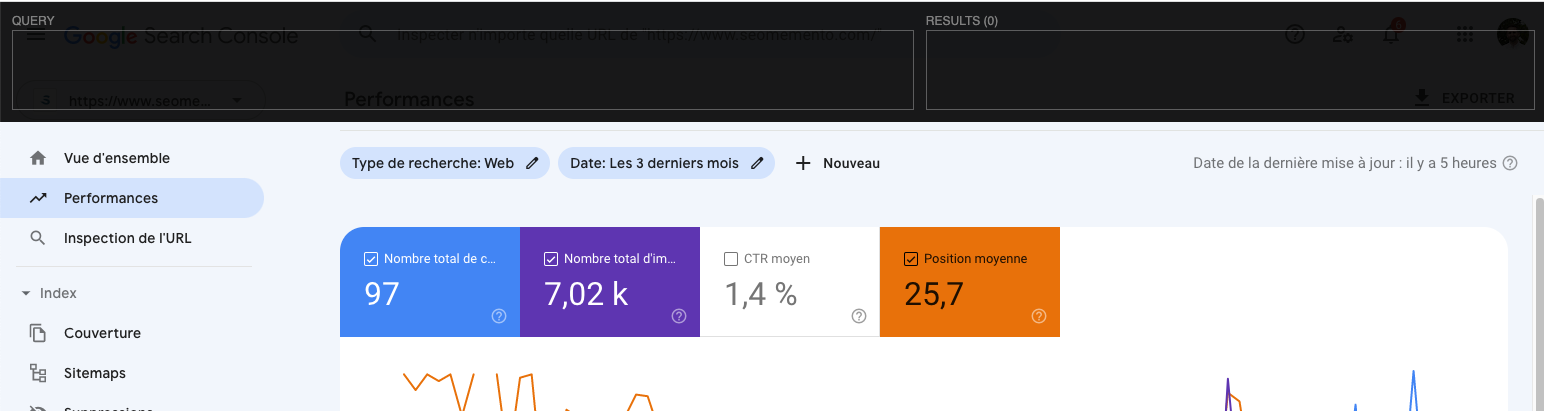
Bon. Attaquons la construction de la requête XPath.
En inspectant le DOM, on remarque que les valeurs de clics, d'impressions, de CTR et de position du rapport Performances de la Search Console sont affichées à la fois :
- dans des balises <td> (ce qu'on voit à l'écran)
- dans des data attributes nommés ici
data-numeric-value(ce qu'on ne voit pas à l'écran)
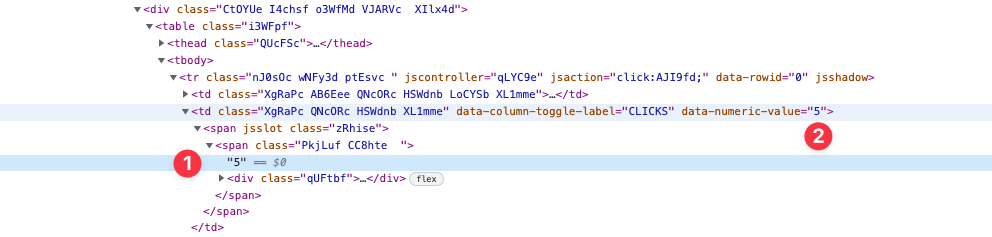
J'ai donc le choix entre ces 2 options pour récupérer les données.
Je vais choisir l'option data attributes car les valeurs sont stockées sous forme de nombres et non de chaînes de caractères. Ça va m'aider pour la suite.
Admettons que je cherche tous les mots-clés avec "moins de 10 clics, plus de 100 impressions et un ranking minimum de 10".
La requête XPath correspondante sera la suivante :
//tbody/tr[td[2][@data-numeric-value<=10] and td[3][@data-numeric-value>=100] and td[5][@data-numeric-value>=10]]Explications :
//tbody/tr: je cible les lignes du tableautd[2][@data-numeric-value<=10]: dont la 2ème cellule (td[2]), celle correspondant aux clics, a un attributdata-numeric-valueayant pour valeur un nombre inférieur ou égal à 10and td[3][@data-numeric-value>=100]: ET dont la 3ème cellule (td[3]), celle correspondant aux impressions, a un attributdata-numeric-valueayant pour valeur un nombre supérieur ou égal à 100and td[5][@data-numeric-value>=10]: ET dont la 5ème cellule (td[5]), celle correspondant à la position moyenne, a un attributdata-numeric-valueayant pour valeur un nombre supérieur ou égal à 10
Bien entendu, tu peux modifier les valeurs en gras selon ton besoin.
2ème solution : la console Chrome
Au lieu d'utiliser un plugin, on peut également arriver au même résultat en passant par la console de Google Chrome.
Je vais utiliser une petite fonction Chrome bien pratique qui permet de sélectionner des éléments correspondants à une expression XPath : $x.
La documentation de cet utilitaire est disponible ici : https://developer.chrome.com/docs/devtools/console/utilities/#xpath-function
Il me suffit :
- d'ouvrir la console (raccourci
⌘ ⌥ I) - d'utiliser la fonction
$x(path)en passant en argument mon expression XPath - de boucler sur chacun des éléments HTML récupérés à l'étape 2 en leur ajoutant un background jaune
Ce qui donne :
var results = $x('//tbody/tr[td[2][@data-numeric-value<=10] and td[3][@data-numeric-value>=100] and td[5][@data-numeric-value>=10]]');
for(var i = 0; i < results.length; i++) {
results[i].style.background = "yellow"
};
3ème solution : un bookmarklet
Allez, je suis sûr qu'au fond de toi tu l'attendais, ce petit bookmarklet !
Bah oui, pourquoi pas lancer un bookmarklet pour aller encore plus vite ?
Plutôt que de surligner les éléments, je vais cette fois supprimer du DOM tous les mots-clés qui ne correspondent pas à ma recherche. L'objectif étant d'avoir un vrai effet de filtre sur la page.
Le fonctionnement du bookmarklet est le suivant :
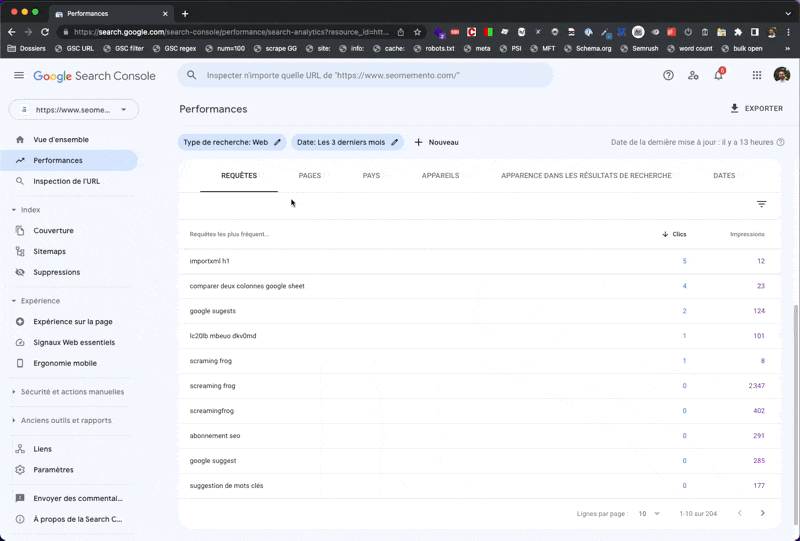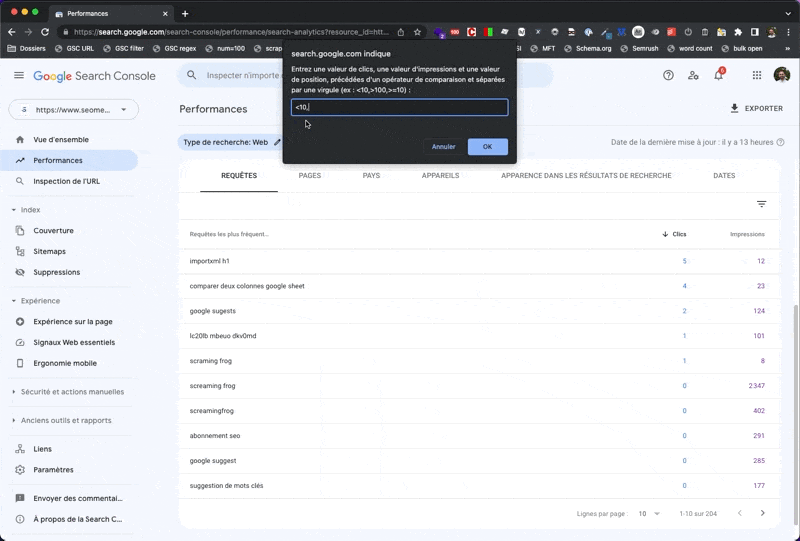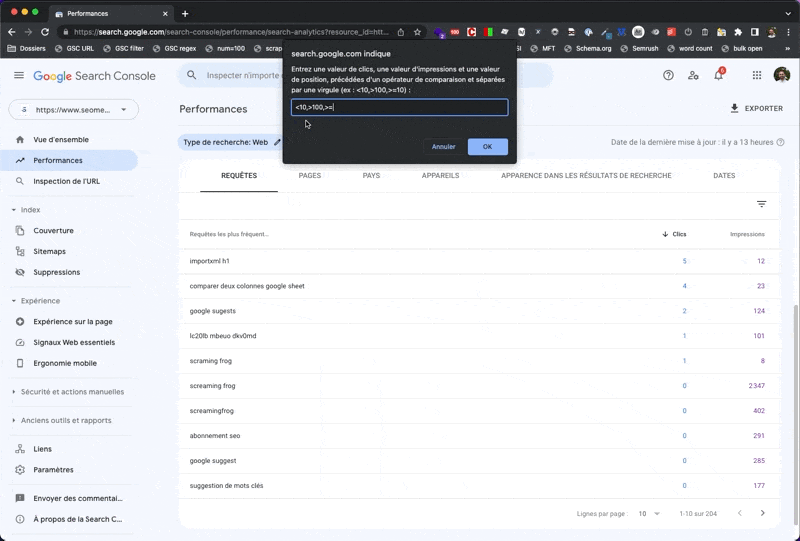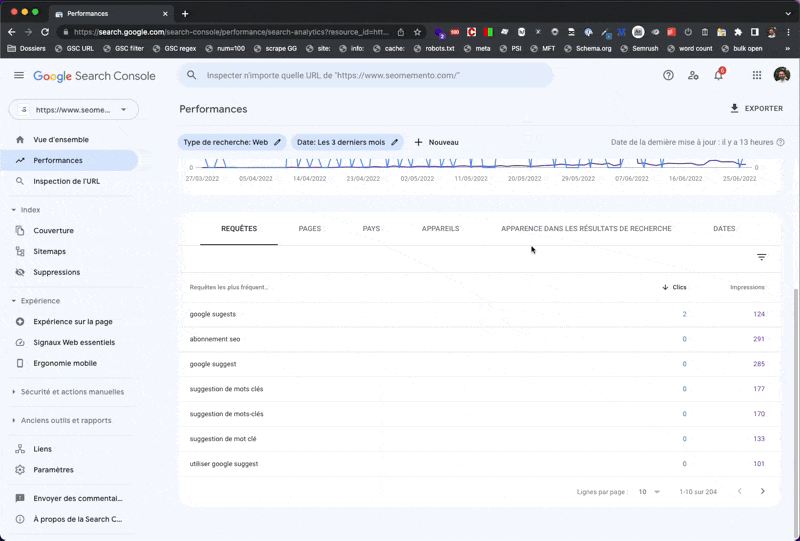
- j'entre mes valeurs dans un
prompt, chaque valeur étant séparée par une virgule. Par exemple, pour les requêtes "à moins de 10 clics, plus de 100 impressions et une position moyenne supérieure à 10", je saisis :<10,>100,>10 - je découpe la valeur de retour et je stocke chaque donnée (clics, impressions, position) dans une variable dédiée
- je cherche dans le DOM les éléments ne correspondant pas à mon expression XPath (je génère ce XPath dynamiquement, en utilisant les variables déclarées précédemment)
- je stocke le résultat dans un array
- je boucle sur cet array en supprimant du DOM chacun des éléments
- je fais sauter la limite de 10 lignes pour afficher tous les résultats d'un coup
À noter qu'il faudra rafraîchir la page si tu souhaites créer un nouveau filtre.
Et hop, le petit bookmarklet qui va bien, à glisser dans tes favoris ↓
Extraire la racine et le nom de domaine d'une URL avec Google Sheets (+TEMPLATE)

Table des matières
Aujourd'hui, je te partage un petit tuto pour récupérer la racine et le nom de domaine (ou sous-domaine) d'une URL dans Google Sheets.
C'est toujours intéressant d'avoir ça sous le coude, notamment pour des analyses de backlinks, de domaines expirés, de SERPs, etc.
Si tu veux avoir accès directement au template, c'est tout en bas ↓
Extraire la racine
Formule
=LEFT(A2;FIND("/";A2;9)-1)
Explications
Pour obtenir l'URL racine (root URL), je vais utiliser deux fonctions : LEFT et FIND.
En gros, l'idée c'est de sélectionner tout ce qui se trouve à gauche du 1er slash dans l'URL, sans compter les 2 slashs derrière le protocole HTTP.
Je cherche tout d'abord à déterminer la position du slash avec la fonction FIND. Pour éviter de sélectionner l'un des slashs contenus dans http:// ou dans https://, je passe en 3ème paramètre de FIND le nombre de caractères à partir duquel commencer la recherche.
https:// = 8 caractères.
Il faut donc que je commence à 8+1 = 9.
Ce qui donne : =FIND("/";A2;9).
C'est bon, je connais la position du slash.
Je peux maintenant utiliser la fonction LEFT en lui passant cette position en 2ème paramètre. Objectif : afficher tout ce qui se trouve avant le slash.
Ce qui donne donc : =LEFT(A2;FIND("/";A2;9)).
Si je veux supprimer le slash de fin, il suffit d'enlever 1 caractère au résultat de FIND : =LEFT(A2;FIND("/";A2;9)-1).
Extraire le domaine ou sous-domaine
Formule
=REGEXREPLACE(B2;"https?\:\/\/";"")
Explications
Ici c'est plutôt simple : je vais remplacer la chaîne http:// (ou https://) de l'URL racine par... rien.
J'utilise donc la fonction REGEXREPLACE avec une expression régulière dont la petite subtilité est de rendre le "s" optionnel avec le quantificateur ?.
Sans oublier bien entendu d'échapper les deux points et les slashs.
Et voilà !
Tu peux télécharger le template Google Sheets en cliquant sur le bouton ci-dessous.













































Commentaires
Enregistrer un commentaire
🖐 Hello,
N'hésitez pas à commenter ou vous exprimer si vous avez des trucs à dire . . .👉