Utilisation de Google Sheets comme grattoir Web de base / benlcollins.com
https://www.benlcollins.com/spreadsheets/google-sheet-web-scraper/
Utilisation de Google Sheets comme grattoir Web de base
Vous souhaitez créer un grattoir Web dans Google Sheets ? Il s'avère que le grattage Web de base, la récupération automatique des données des sites Web, est possible directement dans votre feuille de calcul Google, sans avoir besoin d'écrire de code.
Vous pouvez extraire des informations spécifiques d'un site Web et les afficher dans votre feuille de calcul Google en utilisant certaines des formules spéciales de Sheets.
Par exemple, récemment, j'avais besoin de connaître les auteurs d'une longue liste d'articles de blog à partir d'un rapport Google Analytics, afin d'identifier les auteurs vedettes qui tiraient les pages vues. Il aurait été extrêmement fastidieux d'ouvrir chaque lien et d'entrer manuellement le nom de chaque auteur. Heureusement, certaines techniques sont disponibles dans Google Sheets pour le faire pour nous.
Exemple de base de Web Scraper
Pour les besoins de cet article, je vais démontrer la technique en utilisant des articles du New York Times.
Étape 1:
Prenons un article aléatoire du New York Times et copions l'URL dans notre feuille de calcul, dans la cellule A1 :

Étape 2:
Accédez au site Web, dans cet exemple le New York Times :
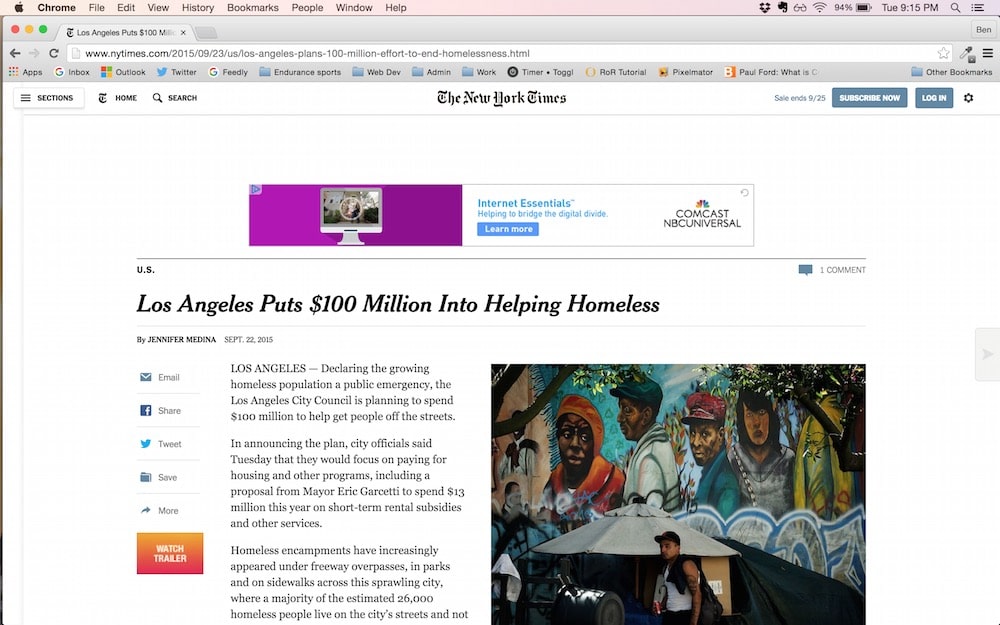
Remarque - je sais ce que vous pensez, n'était-ce pas censé être automatisé ?!? Oui, et ça l'est. Mais nous devons d'abord voir comment le New York Times étiquette l'auteur sur la page Web, afin que nous puissions ensuite créer une formule à utiliser à l'avenir.
Étape 3:
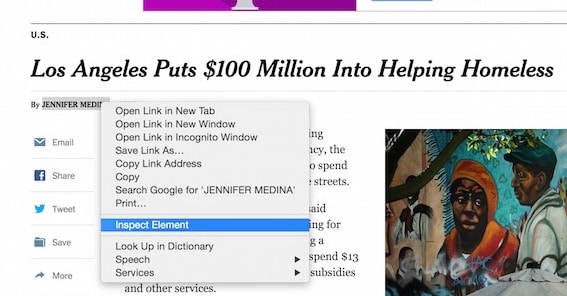
Survolez la signature de l'auteur et faites un clic droit pour faire apparaître le menu et cliquez "Inspect Element"comme indiqué dans la capture d'écran suivante :
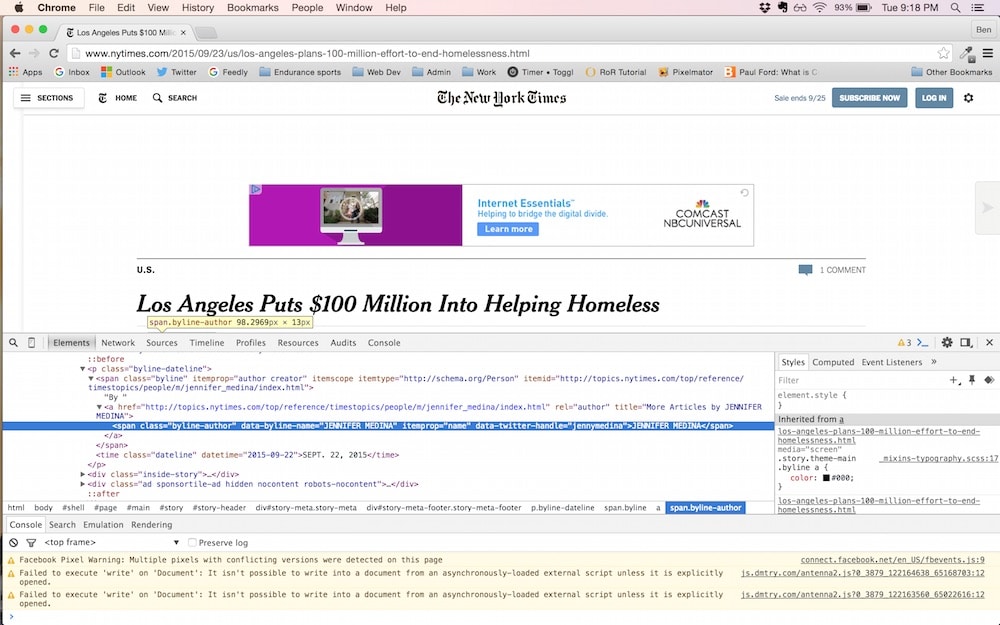
Cela fait apparaître la fenêtre d'inspection du développeur où nous pouvons inspecter l'élément HTML pour le byline :
Étape 4:
Dans la nouvelle fenêtre de la console développeur, il y a une ligne de code HTML qui nous intéresse, et c'est celle en surbrillance :
<span class="byline-author" data-byline-name="JENNIFER MEDINA" itemprop="name" data-twitter-handle="jennymedina">JENNIFER MEDINA</span>
Nous allons utiliser la fonction IMPORTXML dans Google Sheets, avec un deuxième argument (appelé "xpath-query") qui accède à l'élément HTML spécifique ci-dessus.
La requête xpath, //span[@class='byline-author'], recherche les éléments span avec un nom de classe "byline-author", puis renvoie la valeur de cet élément, qui est le nom de notre auteur.
Copiez cette formule dans la cellule B1, à côté de notre URL :
=IMPORTXML(A1,"//span[@class='byline-author']")La sortie finale pour l'exemple du New York Times est la suivante :

Exemple de Web Scraper avec des articles multi-auteurs
Considérez l'article suivant :
http://www.nytimes.com/2015/09/25/us/pope-francis-congress-speech.html
Dans ce cas, il y a deux auteurs dans la signature. La formule de l'étape 4 ci-dessus fonctionne toujours et renverra les deux noms dans des cellules séparées, l'une sous l'autre :

C'est bien pour un cas à usage unique, mais si vos données sont structurées en lignes (c'est-à-dire une longue liste d'URL dans la colonne A), vous devrez alors ajuster la formule pour afficher les deux noms d'auteur sur la même ligne.
Pour ce faire, j'utilise une formule Index pour limiter la requête au premier auteur, de sorte que le résultat n'existe que sur cette ligne. La nouvelle formule est :
=INDEX(IMPORTXML(A1,"//span[@class='byline-author']"),1)Notez que le deuxième argument est 1, qui se limite au prénom.
Ensuite, dans la cellule adjacente, C1, j'ajoute une autre formule pour collecter la deuxième signature de l'auteur :
=INDEX(IMPORTXML(A1,"//span[@class='byline-author']"),2)Cela fonctionne en utilisant 2 pour renvoyer le nom de l'auteur en deuxième position du tableau renvoyé par la fonction IMPORTXML.
Le résultat est:

Autres exemples de grattoirs Web multimédias
D'autres sites Web utilisent des structures HTML différentes, de sorte que la formule doit être légèrement modifiée pour trouver les informations en référençant la balise HTML spécifique pertinente. Encore une fois, la meilleure façon de procéder pour un nouveau site est de suivre les étapes ci-dessus.
Voici quelques exemples supplémentaires :
Pour Business Insider, la signature de l'auteur est accessible avec :
=IMPORTXML(A1,"//li[@class='single-author']")Pour le Washington Post :
=INDEX(IMPORTXML(A1,"//span[@itemprop='name']"),1)Utilisation de la fonction IMPORTHTML pour gratter des tableaux sur des sites Web
Considérez la page Wikipédia suivante, montrant un tableau des bâtiments les plus hauts du monde :
https://en.wikipedia.org/wiki/List_of_tallest_buildings
Bien que nous puissions simplement copier et coller, cela peut être fastidieux pour les grandes tables et ce n'est pas automatique. En utilisant la formule IMPORTHTML , nous pouvons demander à Google Sheets de faire le gros du travail pour nous :
=importhtml(A1,"table",2)ce qui nous donne la sortie :
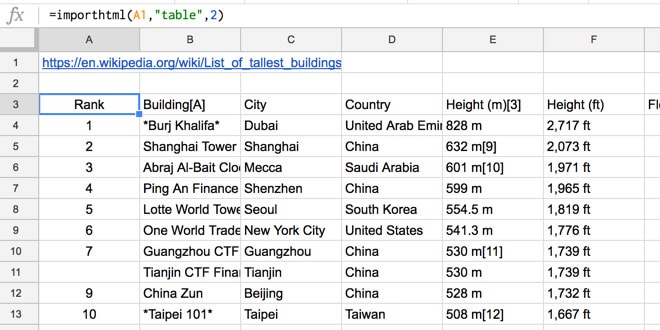
Trouver le numéro de table (dans cet exemple, 2) implique un peu d'essais et d'erreurs, en testant les valeurs à partir de 1 jusqu'à ce que vous obteniez la sortie souhaitée.
Notez que cette formule fonctionne également pour les listes sur les pages Web, auquel cas vous modifiez la référence "table" dans la formule en "liste".
Lectures complémentaires
Pour des exemples plus avancés, consultez :
Comment importer des statistiques de réseaux sociaux populaires dans Google Sheets
Autres formules d'IMPORT :
Si vous souhaitez étendre cette technique, vous voudrez consulter ces autres formules Google Sheet :
IMPORTDATA – importe les données à une URL donnée au format .csv ou .tsv
IMPORTFEED – importe un flux RSS ou ATOM
IMPORTRANGE - importe une plage de cellules à partir d'une feuille de calcul spécifiée.









Existe-t-il un moyen de récupérer des données protégées par un mot de passe, telles que le nombre total d'abonnés dans ma newsletter par e-mail ? Quelle est la syntaxe pour cela ?
Salut Cindy !
Malheureusement, ces formules IMPORT ne peuvent pas fonctionner avec des données derrière un mur de mots de passe. Quel fournisseur de service de messagerie utilisez-vous ? Il est relativement facile de se connecter à l'API MailChimp (je n'en ai pas essayé d'autres) et d'extraire toutes sortes de données d'abonnés aux e-mails de cette façon. Je publierai un article à ce sujet prochainement.
Bravo,
Ben
Salut Ben - cela ne semble pas fonctionner sous forme d'essai de mise au rebut en utilisant votre formule mais je reçois "le contenu importé est vide".
Business Insider a-t-il changé son code ?
Merci,
Salut Dave,
Testé tout à l'heure avec cette URL : http://www.businessinsider.com/what-to-expect-from-apple-q2-earnings-2017-5 et cela fonctionne toujours pour moi. Il a extrait le nom de l'auteur Kif Leswing. Vérifiez que votre formule pointe vers la bonne cellule avec l'URL, par exemple si l'URL est en A1, mettez A1 dans la formule IMPORT. L'article avait à l'origine A19 dans la formule, ce qui peut avoir été trompeur.
Bravo,
Ben
Salut Ben. J'essaie d'utiliser une partie de votre message pour créer une certaine formule, mais j'ai du mal. Peut-être que vous pourriez aider. J'aimerais créer une formule Google Sheets pour extraire des données en direct de Yahoo Finance afin d'obtenir certaines informations sur les actions. La fonction "Googlefinance" n'affiche pas tout ce dont j'ai besoin et elle présente également des données décalées d'au moins 20 minutes par rapport au temps réel. Quoi qu'il en soit, je veux que ma formule affiche les pourcentages YTD, 1 mois, 3 mois, 6 mois, 1 an, 3 ans, 5 ans, 10 ans et maximum de retour sur investissement. J'aimerais que la formule affiche ces résultats dans une colonne et recherche les données de Yahoo Finance en fonction des symboles boursiers que je saisirais manuellement dans une autre colonne. Un exemple serait que je taperais manuellement "ZROZ" dans la cellule A1 et la formule donnerait les cellules B1: J1 avec toutes les données en direct de Yahoo Finance. Le site est https: // finance.yahoo. com/quote/ZROZ/ performance?p=ZROZ
Des idées??
Ben, bonjour.
comment prendre une cellule du tableau et la diriger vers le site, par exemple, A1 est la ligne de connaissance du produit, A2 est le prix du produit.?
Salut Ben,
Si j'ai besoin de me connecter à un tas de sites Web (à cause des abonnements) puis de télécharger du contenu en fonction d'un critère qui m'intéresse, puis-je le faire avec l'API Mailchimp et si oui, comment puis-je faire cela ?
Les étapes que j'envisage sont les suivantes :
1. Ouvrir des feuilles de calcul google
2. Créer une liste de sites Web avec les colonnes de noms d'utilisateur et de mots de passe dont je veux récupérer mon contenu
3. Exécuter les formules (avec une sorte de commande d'exécution, je suppose), c'est-à-dire, effectuez l'importation
4. Enregistrez tout le contenu sur mon Google Drive
5. Exécutez mon critère sur ces documents, par exemple, des documents PDF, des fichiers ZIP, etc., ou un tableau récapitulatif des informations, puis téléchargez "détail"
6. Enregistrer le contenu détaillé sur vers un autre emplacement sur G-drive.
Merci d'avance,
Salut Ben,
Jolies choses!
Avez-vous déjà publié quelque chose en vous connectant à des sites Web avec un identifiant et un mot de passe ?
Vous vous demandez maintenant que nous sommes en 2020, est-ce toujours le cas ? Vous cherchez à obtenir des données d'un site protégé par un mot de passe. Je me demande si c'est possible si je me connecte d'abord, puis exécute la commande ?
Bonjour Ben,
j'aimerais demander votre aide. J'ai utilisé IMPORTHTML sur ce site Web - https://www.bursamalaysia.com/market_information/equities_prices?keyword=&top_stock=&board=MAIN-MKT&alphabetical=§or=&sub_sector=&sort_by=short_name&sort_dir=asc&page=1&per_page=50 .
Mais je reçois le message "Impossible de récupérer l'URL…". S'il vous plaît des conseils.
Hey ben,
Comment collectez-vous manuellement des données brutes et les mettez-vous facilement dans des feuilles Google ?
Salut Ben,
Comment feriez-vous pour saisir le prix « Client Buys » sur ce site : https://www.tdcanadatrust.com/customer-service/todays-rates/rates.jsp
J'ai essayé plusieurs choses différentes sans succès.
Salut Dave,
Malheureusement, je n'ai pas non plus été en mesure de récupérer les données d'achat du client. Je pense que le problème est que le contenu de la page est généré dynamiquement (c'est une page Java Server ou .jsp, ce qui signifie que le contenu est créé par programme), de sorte que les formules d'importation ne peuvent pas analyser ces données.
Je vous tiendrai au courant si quelque chose fonctionne !
Bravo,
Ben
Pouvons-nous récupérer des données de Google.com et afficher toutes les URL dans une colonne par rapport à une requête pour, par exemple, je recherche "Usman Farooq"
Je renvoie un #N/A en essayant ceci avec instagram. J'essaie d'importer le nombre de messages pour un hashtag donné. Par exemple, l'URL suivante de https://www.instagram.com/explore/tags/fitness/?hl=en utilisant =IMPORTXML(A2,"//span[@class='_bkw5z']") où A2 est l'URL renvoie #N/A. Des idées?
Salut riche,
Jetez un œil à ce fil de commentaires sur mon autre article IMPORT, qui commence par ce commentaire : https://www.benlcollins.com/spreadsheets/import-social-media-statistics/#comment-31914
et la solution éventuelle est ce commentaire : https://www.benlcollins.com/spreadsheets/import-social-media-statistics/#comment-33035
Laissez-moi savoir si cela fonctionne pour vous…
Bravo,
Ben
Merci Ben! Je vais le vérifier après le travail plus tard ce soir et je vous ferai part de mes résultats.
la feuille ne fonctionne pas, la classe cs a changé, doit être
class = "css-1baulvz"
Bonjour gars,
Je ne sais pas si c'est spécifique à la région (europe) ou google a changé quelque chose (le message a 2 ans), mais j'ai dû utiliser un point-virgule » ; " au lieu de deux-points ", " dans la formule.
Salut Piotrek,
Oui tu as raison! Il s'agit d'un changement régional standard pour la syntaxe de l'Europe continentale.
Bravo,
Ben
Bonjour,
j'essaie d'utiliser cette méthode pour les annonces Street Easy. Le mien fonctionnera, puis je reviendrai à la feuille plus tard et j'obtiendrai le message "
Le contenu importé par erreur est vide". et des idées pourquoi cela pourrait se produire?
Merci
En tant que personne qui utilise la programmation pour le grattage Web, cet article a été très utile. Je commence souvent avec des frameworks complexes comme Scrapy pour Python, sans réaliser qu'il existe des solutions plus simples. Bravo, Simon
Vrai! Bien qu'elles soient limitées par rapport à Python, ces fonctions IMPORT peuvent faire une quantité surprenante. J'ai fait un article de suivi sur le web scraping des statistiques des médias sociaux .
Bonjour ben;
Tout d'abord, je voudrais admettre que ces infos sont géniales et incroyables, merci beaucoup ! et je voudrais vous poser 2 autres questions;
1-Existe-t-il un moyen de récupérer les données d'un site Web comprenant plusieurs pages ?
2- (En fait, cette question dépend de votre réponse à la 1ère question) Donc, s'il existe un moyen de pagination, existe-t-il un moyen automatisé de récupérer les données des pages qui nécessitent une vérification de l'âge (en saisissant la date de naissance) parmi ces multiples pages?
Désolé pour mon mauvais anglais j'espère qu'il est assez bon pour vous faire comprendre mes questions 🙂
Merci d'avance
Salutations
Salut Ozan,
Il n'y a donc aucun moyen pour les formules standard de gérer la pagination et de récupérer les données de plusieurs pages. Potentiellement, vous pouvez modifier l'URL à chaque fois, en fonction de la façon dont elle a été configurée, de sorte que vous puissiez changer le numéro de pagination à chaque fois, par exemple
Dans une cellule mettre https://techcrunch.com/page/2/
puis dans la cellule suivante : https://techcrunch.com/page/3/
Dans la cellule suivante : https://techcrunch.com/page/4/
etc ..
puis exécutez la formule IMPORT pour chacun d'entre eux.
Il n'y a aucun moyen de récupérer des données qui nécessitent d'abord une vérification de l'âge, sans utiliser Apps Script pour le faire par programmation. Les formules IMPORT sont assez basiques (mais puissantes !).
J'espère que cela pourra aider!
Ben
Merci beaucoup pour ta réponse Ben
Salut Ben,
J'essaie de récupérer une valeur pour une crypto-monnaie à partir de cette page
https://bittrex.com/Market/Index?MarketName=BTC-ANS
La valeur que je veux est dans le html comme ceci
0.00203969
J'ai essayé quelques syntaxes différentes, par exemple this
=importxml(A1,"//span[@span data-bind='text: summary.displayLast()']")
Mais impossible de trouver la bonne syntaxe.
Pourriez-vous aider s'il vous plaît.
Merci
Salut Sean,
Malheureusement, je ne pense pas que ce sera possible avec ces formules IMPORT, car le site Bittrex est généré dynamiquement en javascript côté client. J'ai essayé toutes les astuces que je connais, mais je ne peux obtenir que les parties statiques comme les en-têtes, pas les données. En savoir plus sur ce problème ici : https://www.benlcollins.com/spreadsheets/import-social-media-statistics/#notWorking
Votre prochaine étape serait d'envisager d'écrire un script Apps pour extraire ces données via l'API dont ils disposent (documents ici : https://bittrex.com/Home/Api ).
Bravo,
Ben
Sean - il existe un site alternatif avec les prix Bitcoin, coinmarketcap.com, qui fonctionne pour extraire les données. Jetez un œil à ce fil de commentaires : https://www.benlcollins.com/spreadsheets/saving-data-in-google-sheets/#comment-34170
Peut-être vous sera-t-il utile ?
Merci Ben c'est super, la prochaine question pourrait être idiote mais une fois que j'ai extrait ces données, comment puis-je les utiliser dans une autre formule sur la feuille?
J'essaie de calculer une somme en utilisant cette valeur de prix * le nombre de pièces que je détiens et cela ne fonctionne pas.
Merci!
Salut Sean,
J'ai trouvé cette formule
=IMPORTXML(A1,"//span[@id='quote_price']"), avec l'URL dans la cellule A1, qui fonctionnait bien pour être utilisée dans d'autres formules (par exemple somme). J'ai fait formater la cellule en tant que nombre (ou comptabilité). Vous pouvez également essayer d'envelopper votre formule existante avec la formule VALUE, comme ceci :=VALUE(existing formula in here)J'espère que cela pourra aider! N'hésitez pas à partager votre formule si elle pose toujours problème.
Ben
Désolé Ben tu m'as perdu 🙂
Au Q1 j'ai l'URL http://coinmarketcap.com/currencies/antshares
À O1, j'ai ceci =IMPORTXML(Q1,"//span[@id='quote_price']")
O1 est formaté en tant que financier mais, pour une raison quelconque, a toujours le symbole $
À L13 j'ai une somme de mes pièces
À L15, j'aimerais avoir un calcul et j'ai essayé cela, mais cela ne fonctionne pas = somme (L13 * O1)
Vous ne savez pas ce que vous voulez dire en enveloppant le formala existant avec le paramètre de valeur.
Pouvez-vous expliquer avec un exemple selon mes champs ci-dessus?
Merci beaucoup!
Sean
Salut Sean,
Le $ est juste le formatage qui a été ajouté, c'est toujours un nombre.
Si vous avez votre nombre total de pièces dans la cellule L13, en utilisant la formule SUM, par exemple SUM(L1:L10) disons, alors il vous suffit de multiplier cela par le taux $ de la formule IMPORT dans la cellule O1 pour obtenir la valeur, vous pas besoin d'utiliser la somme ici aussi.
Bravo,
Ben
Je fais manifestement quelque chose de mal….
La valeur L13 est 120
La valeur L10 est 10
à L15 je peux faire =sum(L13*L10) et j'obtiens le résultat attendu de 1200
À O1, j'ai la valeur importée de 8 $
Si j'essaie d'obtenir un total en utilisant cette valeur comme suit = somme (01 * L13)
Au lieu d'un nombre, j'obtiens #VALUE !
Je ne vois pas ou est le problème 🙁
Désolé, je viens de voir ça
Fonction d' erreur
Le paramètre MULTIPLY 1 attend des valeurs numériques. Mais '$8.04' est un texte et ne peut pas être converti en nombre.
J'ai formaté O1 en tant que Number - Financial
Avez-vous une idée de la raison pour laquelle il est toujours traité comme du texte ?
Vous ne savez pas pourquoi le vôtre s'affiche sous forme de texte, vous pouvez donc essayer les deux astuces suivantes partout où vous souhaitez utiliser O1, remplacez-les par :
VALUE(O1)ou
O1 * 1
N'hésitez pas à partager votre fiche si toujours pas de joie !
Salut Ben,
Aucune de ces choses n'a fonctionné.
S'il vous plaît jeter un oeil ici, je pense que cela s'explique d'eux-mêmes quels champs sont cassés.
https://docs.google.com/spreadsheets/d/1JYFWwBgiyByOOlxU_BuwZZmVLHOKTx0Nk9_65q4Ax7c/edit?usp=sharing
Merci beaucoup!
Salut Sean,
Honnêtement, je ne sais pas pourquoi il est importé sous forme de texte avec un "$" devant et n'est pas reconnu comme un nombre. Quoi qu'il en soit, voici une nouvelle formule qui ne traitera que de ce problème (j'ai mis à jour votre feuille avec la formule dans la case jaune):
=iferror(value(IMPORTXML(Q3,"//span[@id='quote_price']")),value(substitute(IMPORTXML(Q3,"//span[@id='quote_price']"),"$ ”,””))))
J'espère que cela pourra aider! Une fois trié, je supprimerai le lien vers votre feuille des commentaires ici.
Bravo,
Ben
Salut Ben,
Merci pour l'exemple. J'essaie d'obtenir le seul numéro disponible dans cette URL : https://blockexplorer.com/api/status?q=getDifficulty
Lorsque je clique sur "inspecter l'élément", il ne semble pas avoir de balises, d'en-têtes et il n'est même pas défini explicitement comme un document HTML ou XML - c'est juste du texte brut ! Et je ne trouve pas la bonne syntaxe en utilisant la fonction IMPORTXML pour que Google Sheets l'aime. Je n'arrête pas d'obtenir un #N/A ou #VALUE !
J'ai essayé de mettre des caractères génériques et d'autres choses, mais je n'arrive pas à le faire fonctionner…
Salut Daniel,
En supposant que vous ayez cette URL dans la cellule A1, vous pouvez utiliser cette formule pour obtenir les données dans votre feuille :
=importdata(A1)Pour extraire uniquement le nombre, essayez la formule suivante :
=regexextract(importdata(A1),"\d+.\d+")J'espère que cela pourra aider!
Ben
Tu es l'homme, Ben ! Fonctionne comme un charme.
Salut Ben,
c'était très utile.
J'ai une question. Comment puis-je obtenir plusieurs données à partir d'une page Web.
Par exemple : je souhaite extraire toutes les URL des images et les balises alt correspondantes d'une liste de pages Web.
Pourriez-vous s'il vous plaît expliquer?
Merci
Abarna
Salut Ben,
J'ai un problème similaire à ceux ci-dessus concernant les feuilles de Crypto Currency. J'ai réussi à extraire les valeurs actuelles de coinmarketcap.com et cela fonctionne bien. Cependant, j'essaie maintenant d'extraire des données d'un autre site https://www.cryptocompare.com/coins/ndc/overview pour être précis, en utilisant cette formule - =IMPORTXML(J23,"//div[@class=' valeur de prix']").
Je suis presque sûr d'avoir fait une erreur fondamentale, mais je n'ai découvert que c'était possible qu'hier….lol J'ai parcouru youtube et les forums pour trouver une solution et je suis tombé sur celui-ci… Ce qui précède est le meilleur que j'ai réussi à trouver. Toute aide à ce sujet serait appréciée.
Acclamations
Carlton
Salut Ben,
Merci d'avoir répondu à toutes les questions, j'ai un problème pourriez-vous s'il vous plaît le résoudre.
Problème : J'essaie de récupérer des données à partir de l'URL de Google Maps ( https://www.google.com/maps/place/Inox+Movies+-+LEPL+Icon/@16.5027383,80.657804,17z/data=!3m1!4b1!4m5 !3m4!1s0x3a35fac8af6a8e6f:0x31b258f18dfbe910!8m2!3d16.5027383!4d80.6599927 )
à partir de cette URL, je voudrais que le nom de l'entreprise soit au format ci-dessous
(Inox Movies - Icône LEPL)
La formule est
=query(importxml(A1,"//h1[@class='section-hero-header-title']"))Je ne reçois aucune donnée (montrant : ErrorImported content is empty.) Veuillez donc vérifier une fois et nous corriger ce que nous faisons mal.
Merci d'avance…
Salut Sivaji,
J'ai également essayé d'extraire ces données, mais malheureusement, je n'ai pas pu non plus. Pas sûr que ce soit possible avec ces formules IMPORT
Salut Ben,
Merci pour l'article, il a l'air génial et il semble que tu répondes à toutes les questions des débutants !
J'essaie de faire ceci :
1. la page Web suivante ( http://www.gcatholic.org/events/year/2017.htm#end ) répertorie toutes les nominations et démissions des évêques de l'Église catholique.
2. Je souhaite importer régulièrement dans une feuille de calcul Google le prénom, le nom, le titre et le pays des derniers évêques nommés (et uniquement les nommés, pas les informations concernant ceux qui ont démissionné ou autre).
J'essayais de le faire moi-même après avoir lu votre article, mais c'est plus compliqué que je ne le pensais, et je suis plutôt débutant.
Merci pour toute aide,
Cédric
Hi Cédric,
Vous pouvez utiliser cette formule pour obtenir rapidement toutes les données de cette page dans votre feuille de calcul Google :
=importhtml("http://www.gcatholic.org/events/year/2017.htm","table",4)Cela devrait vous faire gagner du temps. Le moyen le plus rapide d'extraire ensuite les détails de ces données est probablement manuellement, car les données ne sont pas structurées, c'est-à-dire textuelles, elles changent donc d'une ligne à l'autre.
J'espère que cela pourra aider!
Ben
Merci Ben.
Votre formule fonctionne en quelque sorte, mais je suppose que j'étais trop ambitieux en voulant importer à partir d'une page non structurée.
Cédric
Bonjour Ben,
Votre article est vraiment utile. Merci d'utiliser la fonction de requête ici. Malheureusement, votre suggestion ne peut pas résoudre mon problème. Je veux vous expliquer avec cette image ci-dessous :
https://cdn.pbrd.co/images/GNYpBTL.jpg
Je récupère des données du thésaurus de Collins pour différentes collections de mots. Lorsque je récupère les données de Collins, j'obtiens plus de 15 synonymes et leurs exemples respectifs dans une nouvelle colonne avec chaque synonyme dans une nouvelle ligne. L'image ci-dessus contient des synonymes et un exemple respectif de synonyme dans les 3e et 4e colonnes couvrant toutes les lignes des 3e et 4e colonnes de la feuille pour un seul mot Constitution. Comme il entre dans de nombreuses lignes, je ne peux pas utiliser la fonction Importxml sur d'autres lignes pour différents mots dans l'image. Avec votre exemple, il devient fastidieux d'ajouter un décalage à 15 synonymes différents. Donc, ce que je veux, c'est gratter les données de la manière dont tous les synonymes et leurs exemples respectifs dans une seule ligne elle-même. Y a-t-il un moyen de le faire?
Salut Bharat,
Essayez d'envelopper votre fonction avec la
transposefonction, elle ressemblera donc à ceci :=TRANSPOSE(IMPORTXML(...))Cela devrait transformer les données en deux lignes pour vous. Il est beaucoup plus complexe d'obtenir ces données dans une seule ligne dans le bon ordre, mais c'est possible. Jetez un oeil à cette feuille d'exemple : https://docs.google.com/a/benlcollins.com/spreadsheets/d/1e-mjf_HNWyYvkhFYWqRb2lTanAx77l-YXZO1YYPs71w/edit?usp=sharing
J'espère que cela pourra aider!
Ben
Bonjour, super article et ressources B.
Connaissez-vous la fonction importxml Google Sheets pour identifier si le site utilise un schéma VideoObject comme celui-ci ?
{
"@context": "http://schema.org",
"@type": "VideoObject",
"name": "Title",
"description": "Video description",
"thumbnailUrl": [
"https: //example.com/photos/1×1/photo.jpg »,
« https://example.com/photos/4×3/photo.jpg »,
« https://example.com/photos/16× 9/photo.jpg"
],
"uploadDate": "2015-02-05T08:00:00+08:00",
"durée": "PT1M33S",
"contentUrl": "http://www.example.com /video123.flv",
"embedUrl": "http://www.example.com/videoplayer.swf?video=123",
"interactionCount": "2347"
}
James - pouvez-vous partager l'URL ? Difficile de savoir sans le contexte…
Ben, il semble que vous soyez la personne vers qui se tourner pour extraire des données de pages Web. Voici donc :
1. J'ai une liste d'entités commerciales dans une feuille Google et le nom de l'entité commerciale est un lien hypertexte et je souhaite extraire le lien hypertexte vers une cellule de la même ligne.
2. Le lien qui vient d'être discuté ci-dessus m'amène ensuite à une page contenant des informations sur cette entité commerciale - voir cet exemple - http://www.americanwineryguide.com/wineries/bridge-press-cellars/
3. Je cherche à les détails d'extraction tels que l'adresse, l'e-mail, le téléphone, la fondation, les cas, etc. dans les cellules de la même ligne.
Qu'est-ce que tu penses?
Salut Doug,
Oui, cela devrait être possible, en fonction de l'URL que vous avez partagée. La formule IMPORT pour extraire les données de cet exemple est la suivante :
=importxml(A1,"//div[@id='winery_detail_box1a']")Cela
//div[@id='winery_detail_box1a']peut varier pour différents sites Web, vous devez donc utiliser la fonction Inspecter l'élément pour trouver l'identité de l'élément (voir le message ci-dessus).Bravo,
Ben
Bonjour ben!
Merci pour un guide très utile! J'ai testé cela sur plusieurs pages et cela fonctionne parfaitement.
Cependant, j'échoue continuellement sur ce site (en suédois)
http://www.morningstar.se/Funds/Quicktake/Overview.aspx?perfid=0P00009NT9&programid=0000000000
J'essaie d'extraire par exemple le tableau avec "Årlig avkastning %" comme titre. En fait, je ne peux rien extraire de cette page sans utiliser IMPORTDATA.
De plus, les addons chromés, par exemple Scraper, peuvent extraire avec le XPath
"//*@id="ctl00_ctl01_cphContent_cphMain_quicktake1_col1_ctl00_ctl04″]/table"
Mais j'échoue dans ma feuille de calcul Google, donc je soupçonne que cela a quelque chose à voir avec Java ?
Avez-vous des propositions?
Salut Émile,
Si vous utilisez la fonction IMPORTDATA et faites défiler les données (ligne 1075 pour moi), vous verrez le tableau de données pour Årlig avkastning %. Cependant, ce n'est évidemment pas très utile dans ce format. Vous pourrez peut-être extraire avec des formules REGEX mais ce serait assez difficile à faire…
Vous avez raison de dire que la fonction IMPORTXML ne semble pas pouvoir renvoyer quoi que ce soit. Probablement parce que la page est (partiellement) générée par javascript.
Bravo,
Ben
J'essaie de récupérer les données boursières à partir de ce lien
http://www.bitcoinrates.in/
mais je n'obtiens pas les prix des actions, juste le nom est de retour J'utilise ceci
=importxml("http://www.bitcoinrates.in/", "//tr[@class='exchange_row']")Hey Ritu - Malheureusement, je ne pense pas que vous puissiez le faire avec ces formules. Les valeurs sont générées par javascript, de sorte que les valeurs réelles
tdetspanne sont que des espaces réservés vides dans lesquels le javascript peut insérer des valeurs. Si vous essayez de le faire=importdata("http://www.bitcoinrates.in/"), vous verrez que les tables sont vides.Salut Ben - Ceci est incroyablement utile. Merci pour le post.
J'ai récupéré de https://comicbookroundup.com/comic-books/reviews/dc-comics/action-comics-(2011) où l'url est en D2 sur Google Sheets en utilisant
=importxml(D2,”//td[@class='rating']”)
Une suggestion sur la façon de gratter un numéro individuel (ex : #1) afin que je puisse tous les afficher individuellement ?
Merci x 1000
– Robi
Salut Robi,
Enfin rattrapé les commentaires.
Vous feriez peut-être mieux de saisir toute la table en utilisant la formule IMPORTHTML comme ceci :
=importhtml(A1,"table",2)De cette façon, vous obtenez toutes les colonnes.
Si vous souhaitez ensuite extraire une entrée spécifique, vous pouvez utiliser la fonction QUERY pour l'extraire :
=query(importhtml(A1,"table",2),"select * where Col2='#52'")où dans ce cas j'ai précisé que je veux #52.
J'espère que cela pourra aider!
Ben
Salut je-
Comment puis-je importer dans googlesheets à partir de ce site : https://www.covers.com/Sports/NBA/Matchups?selectedDate=2017-12-04
J'essaie d'importer une table mais j'obtiens toujours des erreurs. J'ai ouvert le code source mais je n'ai pas pu déterminer quelle # table extraire.
Salut,
Merci pour le partage d'informations utiles !!
HI BEN,
JUSTE BESOIN DE SAVOIR S'IL YA UN MOYEN DE TIRER TOUTES LES DONNÉES DES PAGES WEB AVEC UNE FONCTION IMPORTXML, ??
CORDIALEMENT
Salut Ben,
est-il possible de faire la même chose à partir de Google Trends et si un graphique linéaire du site Web peut être extrait sous forme de tableau à l'aide de importxml ()
merci
Sid
Bonjour
, j'ai un problème, peut-être que vous pouvez m'aider…
demandez à écrire ici - https://docs.google.com/spreadsheets/d/1N83IqaBJNiQtyEhDtszTkG8JZUeJkAHjbTjnfM9-1_o/edit#gid=235706254
il s'agit de =IMPORTXML ou =IMPORTHTML ou =IMPORTDATA
Salut Andrii,
Il faut généralement beaucoup d'essais et d'erreurs pour trouver la bonne fonction !
http://www.bursamalaysia.com/market/listed-companies/list-of-companies/plc-profile.html?stock_code=5218
Je ne peux pas saisir le dernier prix effectué. J'obtiens #N/A. S'il vous plaît aider
Salut Ben,
Merci beaucoup pour ton article.
J'essaie d'extraire des données d'un site Web avec une liste d'attributs comme celle-ci :
Design :
bottes d'hiver
Utilisation recommandée : tous les
jours ; Loisirs; Randonnée hivernale
Tous les éléments ont la même classe. Comment puis-je résoudre ça?
Salut Ben,
Wow, c'est un article super intéressant…. Je ne suis pas non plus un assistant Google Sheets, mais même un débutant comme moi peut voir à quel point quelque chose comme ça pourrait devenir puissant.
Si je veux vérifier l'état de l'URL/du lien (similaire à ce post… https://medium.com/@the.benhawy/how-to-use-google-spreadsheets-to-check-for-broken-links-1bb0b35c8525 ) pour des centaines d'URL à la fois, le site Web n'interdirait-il pas mon IP ?
Je me demande simplement si j'utilise ces codes/formules "fetchURL" ou "IMPORTXML" sur ma feuille de calcul Google, est-ce que je n'aurai pas de problèmes avec le site que je gratte ? Google Sheets utilise-t-il l'adresse IP de mon ordinateur portable pour effectuer ces commandes de récupération d'URL ou puis-je exécuter en toute sécurité des centaines de ces vérifications à la fois ?
J'ai des centaines de liens pointant vers le même site sur ma feuille en ce moment, donc si je crée la formule et que je la fais glisser vers le bas de ma feuille, j'ai peur que mon adresse IP soit bannie !
Merci pour votre temps et votre attention avec ma question NOOB et encore une fois, excellent travail sur ce post.
Ben,
Ceci est une excellente ressource! Merci. Je me demande si vous pouvez me dire si les données de ce site Web - http://www.bet365.com (en particulier, dites les données de la NBA : https://www.bet365.com/?lng=1&cb=10326513237#/AC /B18/C20448857/D48/E1/F36/P ^48/Q^1/I) – peut être importé dans Google Sheets ? J'ai eu du succès avec d'autres sites mais je n'arrive pas à importer celui-ci. Je suppose que c'est impossible à gratter, mais pouvez-vous confirmer?
Merci!
Chris
Salut Chris,
Ouais, je n'ai pas réussi à faire fonctionner celui-là non plus. ¯\_(ツ)_/¯
Ben
salut, merci de partager un article aussi utile. mais peut importer des formules peut être utilisé dans un cas d'utilisation dans lequel l'utilisateur remplit le formulaire Google, concernant ses données personnelles et après avoir rempli les détails, il paiera pour ses affaires via paytm, et parallèlement tous les détails ont été stockés dans google feuille, mais une fois le paiement effectué sur paytm, puis dans google feuille cette colonne est mise à jour automatiquement avec un statut de « paiement reçu », qui a effectué le paiement.
est-ce possible avec la mise au rebut Web. s'il vous plaît laissez-moi savoir
j'espère que je suis en mesure d'expliquer le cas d'utilisation.
Salut Ben - guide IMPRESSIONNANT !
Pouvez-vous m'aider, j'ai essayé plusieurs façons d'extraire le classement des ventes d'Amazon, mais quelque chose ne va pas ! Merci
https://productforums.google.com/forum/#!topic/docs/8k-FcuXgbNw
Salut Naem,
Essayez cette formule pour récupérer toutes les données de classement Amazon :
=index(importhtml($A$2,"list",10),9,1)Cela utilise ImportHtml pour extraire la liste de la page Amazon qui contient les données de classement, puis utilise un wrapper Index pour extraire la 9e ligne du tableau, qui contient les données de classement.
Pour obtenir un numéro de classement individuel, étendez-le à ceci :
=value(regexextract(index(split(index(importhtml($A$2,"list",10),9,1),"#"),1,2),"[0-9,]+"))Cela divise le résultat par le "#" pour obtenir les différents classements, Index pour obtenir la partie pertinente du tableau, puis Regexextract pour saisir les nombres et Value pour les convertir de chaînes en valeurs.
J'espère que cela pourra aider!
Ben
Salut Ben,
Pouvez-vous aider à récupérer le Bestseller-Rang d'Amazon dans cet exemple ?
https://www.amazon.de/dp/1729361862
Devrait être "1.151" mais en utilisant votre formule j'obtiens #N/A
Merci, Dominique
Merci Ben, très bon article et je m'en suis servi mais je suis aussi frustré par l'erreur "Chargement". Ce n'est même pas cohérent. Avez-vous une idée de comment le contourner, peut-être?
Merci Onder. Oui, ces formules peuvent être capricieuses, mais je ne suis pas sûr que vous puissiez y faire quoi que ce soit. Une fois que vous les avez utilisées pour rassembler vos données, je vous suggère de les convertir en valeurs statiques, afin de ne pas perdre les données si la formule cesse de fonctionner.
Comment importer un prix spécifique d'un site Web vers Google Sheets
Ex :
le site Web est "https://www.amazon.in/gp/product/B06W55K9N6/ref=ox_sc_act_title_4?ie=UTF8&psc=1&smid=A14CZOWI0VEHLG"
l'étiquette de prix est de 5899 et son
xpath est //*[@id="priceblock_ourprice"]
mais quand j'utilise la formule
=IMPORTXML( https://www.amazon.in/gp/product/B06W55K9N6/ref=ox_sc_act_title_3?ie=UTF8&psc=1&smid=A14CZOWI0VEHLG , //*[@id="priceblock_ourprice"])
me donnant #ERROR !
Salut Ben! Merci pour cet article éclairant. Je me demandais si cette formule de grattoir Web fonctionnerait avec des sites Web comme SimilarWeb, où je souhaite extraire la valeur entière de la quantité de trafic qu'un site Web spécifique reçoit, comme indiqué dans les résultats de SimilarWeb ? Merci!
Bonjour ben
Vous vous demandez si cette méthode ou une méthode similaire fonctionne pour extraire des données spécifiques de documents pdf. J'ai besoin d'un système similaire pour saisir les données de ma feuille Google dans les données d'un site Web, cliquer sur un lien spécifique sur deux pages consécutives, puis effacer les données d'un pdf.
Le site Web est http://nycprop.nyc.gov/nycproperty/nynav/jsp/selectbbl.jsp
Par exemple
Arrondissement : 1
Bloc : 40
Lot : 3
Page 1 - Voir la facture trimestrielle de taxe sur les biens (QTPB)
Page suivante - Cliquez pour voir l'
adresse postale QPTB Scrub à partir du pdf
Salut je
Ceci est incroyable! a résolu tant de problèmes pour moi!
Les données sont-elles automatiquement actualisées au fur et à mesure de leur mise à jour sur la page d'où elles proviennent ou y a-t-il du travail supplémentaire à faire pour les mettre à jour régulièrement ?
Acclamations
Bonjour Geordie,
Par défaut, ces fonctions recalculent comme suit :
ImportRange : toutes les 30 minutes
ImportHtml, ImportFeed, ImportData, ImportXml : toutes les heures
En savoir plus dans la section docs ici : https://support.google.com/docs/answer/58515
Bravo,
Ben
La formule importHtml peut-elle être déclenchée dans un intervalle de 1 minute à l'aide de n'importe quel script ?
Salut Ben,
Ce fut une très bonne expérience de lire et de regarder votre matériel de formation et de soutien.
1. J'ai une requête en utilisant IMPORTXML, comment pouvons-nous remplacer un point de données vide ou manquant dans une liste de données entière par une valeur ou "NA" ?
2. Comment pouvons-nous extraire l'image SRC ou le lien de l'image dans la feuille de calcul à l'aide de IMPORTXML
Merci d'avance!
Navdeep
Salut moi,
Je veux importer une table à partir du Web. Je peux le faire en utilisant la formule importhtml. Mais il ne se met pas à jour automatiquement, même en définissant un déclencheur avec GAS. Pouvez-vous m'aider à mettre à jour le tableau automatiquement une fois qu'il est mis à jour sur le Web ?
Merci
Salut,
je veux récupérer tous les noms de la liste des membres d'un groupe Facebook ?
est possible?
Bonjour Ben, j'espère que vous pourrez m'aider à obtenir les données à droite dans ma feuille de calcul Google : https://www.dukascopy.jp/plugins/fxMarketWatch/?swfx_index
J'ai essayé ce qui suit qui n'a pas fonctionné : =ImportXML(“https://www.dukascopy.jp/plugins/fxMarketWatch/?swfx_index”,”//div[@class='F-qb-Gb']”)
Qu'est-ce que j'ai fait de mal ou est-ce impossible à importer ?
Merci, Olivier
Salut Ben,
J'ai du mal à obtenir des données du site Web ManoMano dans une feuille Google.
J'ai une liste de références ME que je peux facilement combiner avec la requête de recherche pour me donner une url de travail comme : https://www.manomano.fr/recherche/ME4326301
En utilisant Regexreplace et importxml, je peux obtenir le titre mais je cherche à identifier à la fois la catégorie (répertoriée comme fil d'Ariane dans le chemin XML) et le nom du vendeur (qui a //*[@id="js-product-content" ]/div[1]/div[2]/div[3]/div/div/p/a comme chemin xml).
Je n'arrive pas non plus à extraire dans une feuille Google.
Salut Ben, quelle bonne solution, merci! J'ai une question : comment puis-je récupérer le prix de cette source html ? 132,95
€
Oups, le code source html est filtré, bien sûr. C'est le prix (132,95) mentionné sur cette page : https://www.bever.nl/p/fjaellraeven-greenland-top-rugzak-NAAEC80001.html?colour=4324
Hé, j'ai eu un bon jeu et j'ai réussi à extraire le titre sur cette page
https://www.banggood.com/UMIDIGI-One-Max-6_3-Inch-Global-Bands-4150mAh-NFC-4GB-RAM-128GB-ROM-Helio-P23-4G-Smartphone-p-1393215.html?utmid=6224&ID=533906&cur_warehouse=HK
J'essaie d'extraire l'URL de l'image, cependant, aucune des tentatives que j'ai essayées n'a abouti. Des pensées? Aussi, merci beaucoup pour ce guide, il a été extrêmement utile!
Informations très précieuses ! Merci d'avoir mis ensemble. Quel est votre conseil pour scraper un site lorsque la page est partiellement ou totalement générée par javascript ? Y a-t-il un recours ?
Salut ben, ce post est l'un des merveilleux de mon expérience.
J'essaie de gratter une table vers une feuille Google à partir de
https://www.indiainfoline.com/markets/derivatives/long-buildup
xpath query is //table[@class='table table_mkt fs12e mb0′]
Je voulais gratter le tableau des contrats à terme sur actions expiration du mois en cours
Cela ne me donne que des titres et non des données réelles
Pouvez-vous s'il vous plaît examiner cela?
Merci d'avance
Salut, je
Savez-vous comment utiliser Google Sheet pour gratter le nombre de commentaires Youtube et le nombre de partages ? Merci
Bonjour ben,
J'ai essayé d'importer le titre d'une feuille Google dans une autre. Le code source HTML montre File 101218 , donc j'ai utilisé ceci :
=IMPORTXML(I$1,"//span[@class='docs-title-input-label-inner']")
mais il a produit 'Erreur - le contenu importé est vide'
J'ai cliqué avec le bouton droit de la souris dans la vue html de devtools et j'ai vu qu'il y avait un élément de menu Copier> Xpath. J'ai essayé et cela a donné "//*[@id='docs-title-widget']/div/span", que j'ai transformé en formule
=IMPORTXML(I$1,"//*[@id ='docs-title-widget']/div/span”), en corrigeant les guillemets doubles en simples.
Je ne sais pas pourquoi cela est différent de la première version, mais cela a également produit le message "Erreur - le contenu importé est vide". En gardant à l'esprit le code HTML initial que j'ai collé ci-dessus, savez-vous ce qui ne va pas ici, Ben ?
Désolé, le code HTML collé était ce
span class = "docs-title-input-label-inner"> fichier 101218 </span
J'ai supprimé quelques crochets afin qu'il ne soit pas gâché par la validation du formulaire
Si j'utilise IMPORTXML pour le grattage Web, comment puis-je comptabiliser les valeurs vides ou manquantes dans une certaine classe SPAN ? Fondamentalement, je souhaite que cette valeur s'affiche sous forme de cellule vide dans ma feuille de calcul plutôt que de simplement passer à la valeur suivante sur le site Web.
Existe-t-il un moyen d'ajouter des informations telles que le haut et le bas sur le graphique de https://money.cnn.com/quote/forecast/forecast.html?symb=NFLX aux feuilles Google ?
J'ai une liste de texte hypertexte et j'ai besoin d'extraire une adresse, un numéro et un nom du site. Malheureusement, ces informations ne se trouvent pas dans un tableau ou XML… comment puis-je extraire du texte de chaque site individuel qui est séparé par des sauts HTML ?
https://www.nj.gov/dcf/families/childcare/centers/Hudson.shtml
Hey Ben,
Les données seraient-elles mises à jour si les données sur le site Web étaient mises à jour ?
Merci. Cela fonctionne sur papier, mais ne fonctionnera pas pour de nombreux sites dans la pratique. Exemple : =importxml("https://www.amazon.com/dp/B000ND74XA", "//title") donne "Robot Check".
Hé Ben,
je ne parviens pas à importer les données de Mode Analytics dans une feuille de calcul en utilisant votre formule importHTML (url, query, index) afin que vous puissiez me dire comment résoudre ce problème.
pouvez-vous expliquer comment extraire l'URL de certaines images à partir d'une recherche google basée sur un mot-clé ? J'ai une feuille de calcul avec des titres de produits et je souhaite mettre 1 ou 2 URL d'images pour chaque produit dans les cellules à côté des cellules de titre. Les titres des produits seraient les mots-clés.
Salut Ben, est-il possible de récupérer le nombre "Total des visites" de cette page ? https://www.similarweb.com/website/billboard.com#overview
J'ai bidouillé mais je n'arrive pas à le faire fonctionner.
Salut je
Merci pour cette excellente ressource Google Sheets !
Est-il possible de scraper des données une fois par jour sur une page derrière un identifiant ?
Cordialement,
Chris
Salut chris,
Vous ne pouvez pas utiliser ces formules IMPORT pour récupérer des données derrière une connexion. Vous devrez utiliser Apps Script pour vous connecter à l'API de ce service (en supposant qu'il en ait une). Voici une introduction aux API ici : https://www.benlcollins.com/apps-script/beginner-apis/
Bravo,
Ben
Bonjour Ben,
Votre article sur le webscraping et les exemples sont très utiles. Vous êtes sans aucun doute la personne vers qui je peux compter pour extraire des données des pages Web ci-dessous.
URL : https://www.bseindia.com/corporates/ann.html
Dans le menu déroulant de la catégorie, je choisis "Mise à jour de l'entreprise". Lorsque j'inspecte l'élément, je ne trouve pas « Mise à jour de l'entreprise ». Je voudrais faire ce qui suit
1. Grattez toutes les URL de toutes les entreprises sous "Mise à jour de l'entreprise" pour la journée.
2. Grattez toutes les URL d'une liste d'entreprises dans ma feuille Google sous "Mise à jour de l'entreprise" pour la journée. En ce qui concerne cette deuxième requête, disons que j'ai les codes d'entreprise ci-dessous 540691, 535755, 500410, 512599, 542066, 532921, 533096, 539254, 540025. (Les codes d'entreprise sont similaires aux symboles utilisés par NASDAQ comme AAPL pour Apple Inc). Je pourrais allonger la liste.
S'il vous plaît laissez-moi savoir comment casser cela.
Merci
Tundul
Salut Ben!
Vous vous demandiez si vous saviez quel agent utilisateur GoogleDocs utilise lors de l'exécution du scrape ? Je reçois une erreur de récupération, mais le contenu est disponible sous forme de rendu côté serveur, donc je suppose qu'il pourrait y avoir une sorte de restriction IP ou useragent. J'aimerais vérifier cela, mais je ne sais pas si cet agent utilisateur :
Mozilla/5.0 (compatible ; GoogleDocs ; apps-spreadsheets ; http://docs.google.com )
est en effet le seul que Google Sheets utilise ? Une idée? Merci
Bonjour à tous
Est-ce que quelqu'un sait comment je renvoie une liste des URL sur une page donnée. J'ai trouvé comment obtenir une liste des URL, mais elles ne donnent que le texte de l'URL, par exemple le libellé d'un bouton CTA et non l'URL elle-même.
Voici le code que j'utilise pour ce site :
https://www.pizzaexpress.com/wardour-street/book
L'URL ci-dessus se trouve dans la cellule A2 (renvoyant Réserver maintenant pour le 36e lien de la page)
=INDEX(importxml(A2, "//a"),36)
Renvoie Réserver maintenant correctement, mais j'ai également besoin que le lien soit utilisé pour Réserver maintenant.
Merci!
Hé,
Petite question, le tableau que je cherche à importer comporte plusieurs pages. Comment puis-je obtenir toutes les données dans une feuille Google sans qu'elles ne soient coupées aux 50 premières lignes?
Merci
Salut Ben,
J'ai téléchargé votre fichier de solution, mais j'obtiens une erreur : le contenu importé est vide.
Salutations,
Salut Ben,
Mon fichier est un téléchargement de fichier NARA (National Archives) accessible au public, formaté et étendu avec des formules, etc.
Quelques formules "index/match" dans la colonne C et la colonne AB recherchent l'état qui a attribué chaque SSN et l'état de la ville correspondant au code postal de la personne au moment du décès. Colonne C, l'état d'attribution est facile - remplit 100 % du temps. Cependant, la colonne AB accède au tableau de la feuille 2 "Master 5-Digit…" qui comprend plus de 33 000 codes postaux mais en exclut en fait un certain nombre. Jusqu'à 10 % des recherches ne renvoient aucune correspondance. Alors, comment automatiser ?
Je pensais que importxml devrait fonctionner mais comme vous pouvez le voir, je reçois des bêtises. Je ne trouve pas d'exemple qui illustre ce cas d'utilisation : où la page Web spécifique est dynamique en fonction de la valeur à 5 chiffres de la colonne AB. Cela semble super simple conceptuellement. Y a-t-il un moyen que vous pensiez faire pour simplifier la syntaxe par rapport à la façon dont les Googleurs y pensent et l'expliquent ainsi dans les exemples disponibles en ligne ?
J'ai passé des heures sur Youtube et j'ai essayé de travailler sur la syntaxe pour gagner du temps pour rechercher manuellement chaque enregistrement qui n'arrive pas.
J'apprécie toute aide que vous pouvez fournir ou ressource que vous pouvez me diriger.
Merci
Stacey
Voici le fichier : https://docs.google.com/spreadsheets/d/1W12KBmwqVMSkWiAH-0BOnK9tU-M7uE6mO0pcZDjIMMw/edit?usp=sharing
Existe-t-il un moyen d'obtenir des données d'un site Web auquel j'ai accès et qui est protégé par un mot de passe ? par exemple mes données sur Spreaker.com
Pas avec ces formules, malheureusement. Vous devrez vous connecter à l'API du site Web (en supposant qu'ils en ont une) et authentifier votre application. Il existe des outils tiers qui se connectent à certains sites Web (par exemple, supermetrics) ou vous pouvez le coder vous-même avec le script d'applications (voir cet article pour obtenir de l'aide pour démarrer avec apis : https://www.benlcollins.com/apps-script/api -tutoriel-pour-debutants/ )
Salut Ben,
Super article et partage. Je suis très nouveau sur ce sujet et j'aimerais supprimer le cours de l'action et d'autres informations sur les sites suivants :
https://www.gurufocus.com/stock/V/summary
https://www.morningstar.com/stocks/xnys/v/quote
https://sg.finance.yahoo.com/quote/V
https://www2.sgx.com/securities/equities/CRPU
https://www.propertyinvestsg.com/singapore-reit-data/
https://sreit.fifthperson.com/
J'ai essayé de suivre votre exemple mais j'ai donné des erreurs. Les formules peuvent-elles être utilisées pour ces sites ? Serait-il possible que vous me donniez quelques exemples de ces sites pour commencer ?
Merci.
Salut Ben,
Merci d'avoir partagé. C'est très utile.
A)
Pour les sites suivants, je peux récupérer l'intégralité du tableau en utilisant ImportHTML() :
https://www.propertyinvestsg.com/singapore-reit-data/
https://sreit.fifthperson.com/
Existe-t-il un moyen d'obtenir uniquement le prix en fonction d'un stock spécifique ?
B)
Pour le site ci-dessous :
https://sg.finance.yahoo.com/quote/V
Je suis en mesure d'obtenir toute la chaîne, c'est-à-dire
V - Visa Inc. NYSE - NYSE Delayed Price. Devise en USD 189,39+0,23 (+0,12%)À la clôture : 16h00 HNE
Comment obtenir uniquement le cours de l'action ?
C)
Malheureusement, je ne parviens pas à obtenir de résultat (c'est-à-dire #N/A) pour les sites suivants utilisant ImportXML() :
https://www.gurufocus.com/stock/V/summary
https://www.morningstar. com/stocks/xnys/v/quote
https://www2.sgx.com/securities/equities/CRPU
La plupart des prix des actions et des informations proviennent de ces sites. J'apprécie vos conseils sur la façon dont je peux récupérer le cours de l'action ainsi que d'autres informations, par exemple P / E, Quick Ratio, etc. à partir de ces sites.
Dans l'attente de votre réponse.
Merci.
Salut Ben,
Pour le site suivant :
https://sg.finance.yahoo.com/quote/V
Je suis enfin en mesure d'obtenir le cours de l'action en utilisant la formule :
IMPORTXML(Concat(“https://sg.finance.yahoo.com/quote/”,”V”),”//span[@data-reactid=' 14']”)
Cependant, lorsque j'ai essayé de modifier le deuxième paramètre de la fonction Concat en tant que variable et de l'appliquer à une liste de 340 actions, le chargement de toutes les valeurs prend beaucoup de temps et beaucoup s'affichent comme "chargement".
Existe-t-il un moyen plus efficace de récupérer les prix ?
Merci.
Salut Ben!
Est-il possible de récupérer les données de trafic et d'autres données de similarweb.com ? J'ai essayé ceci mais cela n'a pas fonctionné (j'ai vérifié qu'il pointe vers la bonne cellule).
https://www.similarweb.com/website/radarcupon.es
=IMPORTXML(B4,"//span[@class='engagementInfo-valueNumberjs-countValue']")
Merci pour ton aide!
Il semble qu'ils utilisent la même classe pour différentes valeurs, ce qui pourrait être le problème ? Je serais très reconnaissant si vous pouviez me donner un exemple de la formule à utiliser pour cela.
avez-vous pu faire fonctionner cela avec un site Web similaire?
Salut le lever du soleil,
Je ne suis pas Ben mais je suppose que je peux aussi vous aider.
=importxml(B4 ;"//span[@class='engagementInfo-valueNumber js-countValue']")
Veuillez noter le caractère d'espacement entre « …valueNumber » et « js-… ».
Cordialement
Jorn
Merci pour votre aide, Jörn !
Salut Ben,
J'ai essayé d'importer un tableau d'ESPN pour les statistiques des joueurs PGA. L'URL est - https://www.espn.com/golf/leaderboard/_/tournamentId/401155427
et lors de l'utilisation de importhtml, cela me donne les données du classement. Le tableau que je veux provient du 2e onglet de la page - Statistiques du joueur, mais l'URL ne change pas lorsque je clique dessus, je continue donc à obtenir les données du classement. Y at-il un travail autour? Merci
Salut Ben,
Je ne suis pas sûr que ce soit la même formule, mais j'essaie d'extraire le nom de l'entreprise d'un domaine d'entreprise… des idées ?
par exemple, si j'ai le domaine thinkstream.com.au dans une colonne, j'aimerais que le nom de la société ThinkStream apparaisse dans une deuxième colonne.
Merci d'avance!
Salut,
Est-il possible de créer une feuille de calcul qui inclut les données d'une seule page, ainsi que les données des liens de cette page ?
Par exemple, cet ensemble de données montre toutes les personnes incarcérées dans la prison du comté d'Alachua. Le nom de chaque personne renvoie à plus d'informations à leur sujet. Est-il possible de créer un tableau avec le nom de chaque personne, ainsi que des données provenant de la page de chaque personne ?
http://oldweb.circuit8.org/cgi-bin/jaildetail.cgi?bookno=ASO20JBN001149
Par exemple, nom, caution totale, date de réservation, etc.
Merci!!
Salut Ben,
Je me demandais s'il était possible de récupérer les valeurs dans une liste déroulante ?
Merci!
Existe-t-il un moyen de récupérer les frais de carburant d'UPS dans Google Sheet avec la valeur la plus récente.
https://www.ups.com/us/en/shipping/surcharges/fuel-surcharges.page
Cordialement
Benjamin
Salut Ben, merci beaucoup.
Est-il possible d'importer des playlists YouTube ?
Merci
Salut Ben, Je te suis depuis des années maintenant !
Avec Facebook, existe-t-il un moyen de découvrir que le dernier message mis à jour était dans un groupe ?
"Super article. Je vérifiais constamment ce blog et je suis inspiré!
Des informations extrêmement utiles, en particulier la section ultime 🙂 Je traite beaucoup de telles informations.
Je cherchais cette information particulière depuis longtemps.
Merci et bonne chance."
Salut Ben!
EXCELLENT ARTICLE!
J'essaie de récupérer les informations de trafic de Similarweb à partir d'une liste de sites Web.
J'ai du mal à trouver l'identifiant des données, même si je peux le voir clairement sur le site Web.
Pouvez-vous m'aider avec la formule, s'il vous plaît ?
Merci d'avance
Bernard
Cela a fonctionné comme un charme pour moi! Je devais juste expérimenter, comme vous l'avez mentionné, avec le numéro de table dans la fonction importhtml, et cela a parfaitement intégré les données. Exceptionnel! Oh les choses qui nous rendent heureux 😉
Salut les gars! Super guide !
Je cherche à obtenir les valeurs d'osu! Des pages de profil comme celle-ci : « https://osu.ppy.sh/users/5529199/fruits » . J'essaie principalement d'obtenir le classement mondial, le classement des pays et le nombre sous "PP" sur les pages près du graphique linéaire.
J'ai essayé de faire fonctionner la formule importxml pour ces 3 valeurs, mais la plupart des choses que j'essaie renvoient toutes N/A en disant qu'il ne peut pas trouver les valeurs, etc. En regardant les éléments, il semble que les nombres soient enterrés sous beaucoup de couches div, mais toujours pas de chance, même en copiant le Xpath à partir du site.
Quelqu'un a des idées sur la façon dont je peux obtenir ces chiffres? Comme j'essaie de créer une feuille de calcul pour un tournoi que nous organisons et que ces chiffres sont mis à jour régulièrement, la saisie manuelle n'est donc pas vraiment une option.
Merci pour votre dent 🙂
Bonjour Ben, j'essaie d'extraire l'élément de date d'expédition sur la page Amazon : https://www.amazon.co.uk/dp/B00J8I72PQ , mais lorsque j'essaie d'inspecter l'élément, je ne vois pas le texte à déclenchez-le pour afficher la date de livraison, ci-dessous le code que je reçois.
Merci d'avance,
À M
Livraison gratuite
22 septembre – 21 octobrepour les membres Prime
Détails
Cela a fonctionné comme un charme pour saisir les prix des titres de Bloomberg pour les actions TSE non prises en charge par GOOGLEFINANCE. Merci!
De rien! Acclamations.
Bonjour, j'essaie d'extraire les prix du site Aliexpress, est-ce possible ? je ne pouvais pas le faire! Quelqu'un peut-il m'aider?
Il n'y a pas de solution au problème de suppression des visites mensuelles de SimilarWeb ?
:/
Un peu la chose la plus difficile à mettre au rebut..
Salut Ben!
Pouvons-nous obtenir tous les avis de Google Playstore dans Google Sheets ?
Salut Ben,
j'essaie d'obtenir le tableau de https://economictimes.indiatimes.com/marketstats/exchange-nse,marketcap-,pid-40,sortby-indexName,sortorder-desc.cms
J'ai essayé ImportHTML, ImportXML mais n'ont aucun effet. Ce serait bien si vous pouviez me dire s'il peut être importé ou non.
Salut,
Je me demandais s'il existe une formule à utiliser pour obtenir des données d'une autre feuille et filtrer la date en utilisant la date dans la validation des données
Salut Ben! Merci pour votre guide. J'essaie d'utiliser cette formule mais j'obtiens N/A. Comment dois-je formuler le forumla pour sortir le h1 de cette page :
https://wiu.campuslabs.com/engage/organization/159bcm
La sortie devrait être "159 Baptist Collegiate Ministry at WIU"
Merci d'avance!!
Ben,
J'essaie d'extraire le tableau des "statistiques diverses" de https://www.basketball-reference.com/leagues/NBA_2021.html . J'ai pu extraire des tables jusqu'au n ° 4, toute valeur de table que j'utilise après cela ne me fournit aucune information. Je suis allé de l'avant et j'ai tenté jusqu'au n ° 50 en espérant que c'était un accident étrange, mais je l'ai fait sans aucun succès. J'ai essayé de parcourir le code dans l'espoir de trouver la table # et j'ai échoué là aussi….
si vous trouvez un succès dans ce domaine, ce serait formidable !
Merci
Salut! merci pour les informations très utiles, j'essaie de capturer l'autre page Web, et j'ai trouvé difficile les "données dynamiques", qui changent avec le temps, comme le résultat de cette formule,
=importxml("https://www .myethshop.com/", "//*[@id='now_timestamp']")
affiché uniquement "-", pourquoi ?
J'espère que vous pourriez m'aider à résoudre, merci
Salut Ben. Super article!
J'ai une question. Est-il techniquement possible d'extraire la valeur d'un attribut en utilisant cette méthode ?
Merci.
Salut Ben!
Super post a beaucoup appris.
Je suis un projet en Inde où nous organisons des vidéos en ligne pour les enfants qui ne sont actuellement pas scolarisés en raison de la pandémie. Nous avons une liste de vidéos youtube déjà organisées - ce que nous voulons, c'est obtenir les noms de tous les propriétaires de vidéos youtube / noms de chaînes. Est-ce que ce sera possible avec ça ?
https://www.youtube.com/watch?v=dzOP7jliAKM – une de ces vidéos par exemple
Hé! Excellent article. J'essaie d'utiliser votre tutoriel pour saisir une liste de contrôle de cartes de baseball dans un tableau et les mettre dans une feuille. Pourriez-vous jeter un coup d'œil et me faire savoir si votre méthode est possible ici : https://www.psacard.com/psasetregistry/baseball/modern-player-sets-1970-present/nolan-ryan-master-set/composition /1944
Salut Ben, merci pour ton tuto. J'ai essayé le code suivant pour récupérer le résultat du nombre de travaux de Linkedin mais cela ne semble pas fonctionner. Pouvez-vous aider ? Merci
Cellule A1 :
https://www.linkedin.com/jobs/search/?f_TPR=r604800&geoId=105663381&keywords=ux%20designer&location=Surrey%2C%20England%2C%20United%20Kingdom&position=1&pageNum=0
=IMPORTXML(A1,"//span[@class='results-context-header__job-count']")
Hey Ben
Cette approche fonctionnerait-elle pour supprimer les avis Google Workspace ?
Si non, que proposeriez-vous ?
Cela pourrait-il être utilisé pour réduire les prix sur Google Shopping ?
Super contenu, merci ! Grattez-vous FaceBook Marketplace ?
Content de trouver ce contenu. Google Sheets est désormais un incontournable du SEO.
Le problème auquel je suis confronté est si la ligne a td class="bocss-table__td bocss-table__td–data" où le nombre est suivi d'un .