IMPORTHTML, IMPORTFEED & IMPORTXML: EXTRAIRE DES DONNÉES WEB DIRECTEMENT DANS GOOGLE SPREADSHEET
IMPORTHTML, IMPORTFEED & IMPORTXML: EXTRAIRE DES DONNÉES WEB DIRECTEMENT DANS GOOGLE SPREADSHEET
Scraper, selon wikipedia c’est « extraire du contenu de sites Web, via un script ou un programme, dans le but de le transformer pour permettre son utilisation dans un autre contexte ». Extraire des données c’est déjà bien, mais dans un tableau google spreadsheet, c’est encore mieux.
Pourquoi Scraper des données disponibles sur le web ?
Pour 2 raisons principales:
- un simple copier coller ne conserve pas toujours la mise en forme
- en scrapant les données, on peut actualiser très facilement la récupération de données issues de multiples sources
Quelques exemples d’utilisations:
- Extraire les résultats de recherche de Google ou Twitter pour découvrir les concurrents sur son domaine, ou juste mesurer son positionnement
- Extraire un tableau depuis wikipedia pour en exploiter les données
- Extraire la liste des annonces (titre, prix, etc.) d’un résultat de recherche sur leboncoin
- Traduire ses flux RSS en français
- etc.
Google met à disposition 3 fonctions très pratiques pour executer ces taches directement dans google spreadsheet: ImportHtml, ImportFeed & ImportXML.
- ImportHtml: importer facilement des tableaux et des listes
- ImportFeed: importer des flux RSS dans Google spreadsheet
- ImportXml: importer à peu près n’importe quoi dans google spreadsheet
- Télécharger les exemples mentionnés dans l’article

ImportHtml: importer facilement des tableaux et des listes
La fonction ImportHtml est la plus facile à prendre en main: aucune compétence technique n’est nécessaire. Vous pouvez importer 2 types de données depuis n’importe quelle page internet:
- des tableaux (balises html « table »)
- des listes (balises html « li »)
Utilisation de la fonction ImportHtml de Google Spreadsheet
Syntaxe:
=IMPORTHTML(url, requête, index)
- url: l’adresse de la page avec le http (ou une référence à une cellule contenant l’url)
- requête: table ou list, selon que vous vouliez extraire un tableau ou une liste
- index: numéro du tableau de la page (1 si il s’agit du 1er tableau, 2 si c’est le second, etc.)

Growth = Methode x Experience
Luko, Blablacar, Castalie, Legalstart, Numa,... ont tous fait confiance a deux.io dans leur croissance web. Découvrez La 1ere Agence de Growth Hacking de 
Extraire des données Wikipedia dans Google Spreadsheet avec ImportHtml
Exemple d’utilisation:
=IMPORTHTML("http://fr.wikipedia.org/wiki/Parts_de_marché_des_navigateurs_web","table",1)

[zilla_button url= »#exemples » style= »blue » size= »medium » type= »round » target= »_self »] Essayez par vous même ! [/zilla_button]
Pour plus d’information, reportez vous à la documentation Google Spreadsheet ImportHtml
ImportFeed: importer des flux RSS dans Google spreadsheet
La fonction ImportFeed est à peine plus compliquée. Elle permet d’importer un flux RSS dans spreadsheet en spécifiant le type d’info qu’on veut récupérer. La seule complication ici est qu’un flux RSS contient beaucoup de type d’information:
- infos relatives au flux lui même: titre, description, auteur, url
- infos relatives aux items du flux: titre, résumé, url, date de création
Utilisation de la fonction ImportFeed de Google Spreadsheet
Syntaxe:
=IMPORTFEED(url, requête*, en_têtes*, nombre_éléments*)
*champs optionnels. Seule l’url est obligatoire. Si aucun autre paramètre n’est indiqué, spreadsheet importera l’ensemble du flux, 1 type d’info par colonne.
Pour paramétrer un peu plus tout ça & ne récupérer que les infos qui vous intéressent vraiment, voici le détails des champs à passer:
- url: l’adresse du flux RSS, avec le http (ou une référence à une cellule contenant l’url)
- requête: vous pouvez récupérer l’ensemble du flux (valeur par défaut) ou juste une partie de celui-ci:
- feed: retourne l’ensemble des informations concernant le flux (titre, description, auteur et url
- feed title: retourne le titre du flux
- feed description: retourne la description du flux
- feed author: retourne l’auteur du flux
- feed url: retourne l’url du flux
- items (valeur par défaut): retourne l’ensemble des champs des billets inclus dans le flux RSS
- items title: retourne le titre des billets inclus dans le flux
- items summary: retourne le résumé (contenu sans images ni liens) des billets inclus dans le flux
- items url: retourne les urls des billets inclus dans le flux
- items created: retourne la date des billets inclus dans le flux
- feed: retourne l’ensemble des informations concernant le flux (titre, description, auteur et url
- en tête: TRUE (valeur par défaut) pour afficher les en tête de colonnes ou FALSE si vous ne souhaitez pas les afficher
- nombre_éléments: par défaut, l’ensemble du flux sera retourné, amis si vous ne voulez en récupérer qu’un certain nombre, indiquez le ici (ex. 10)
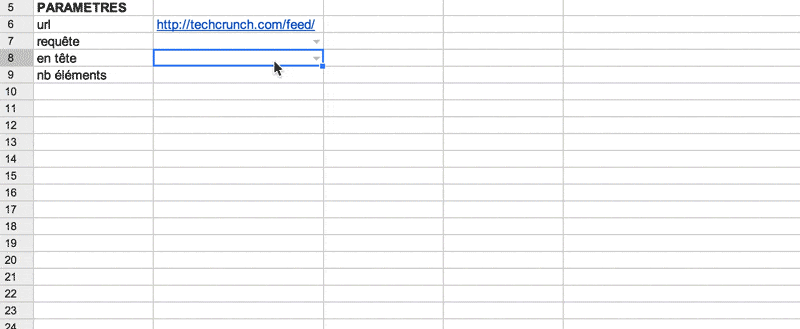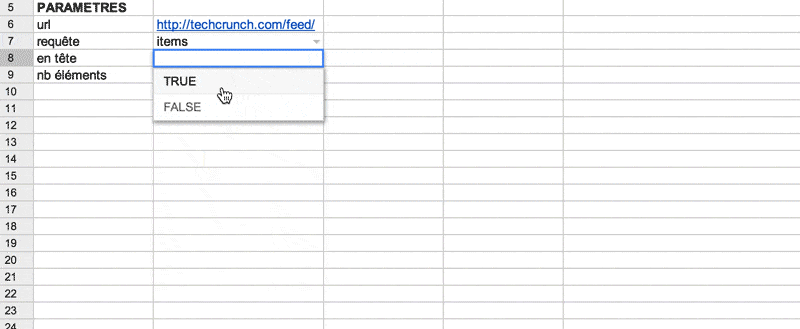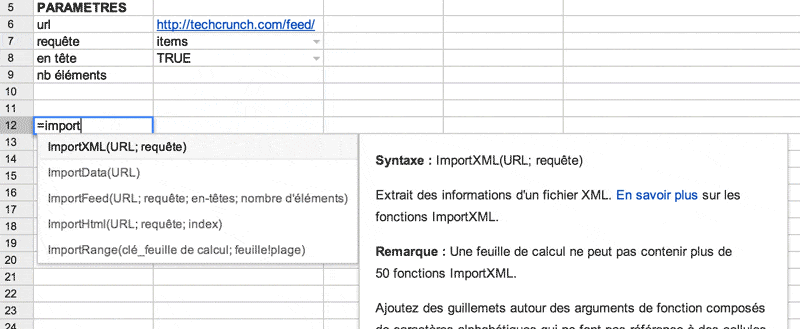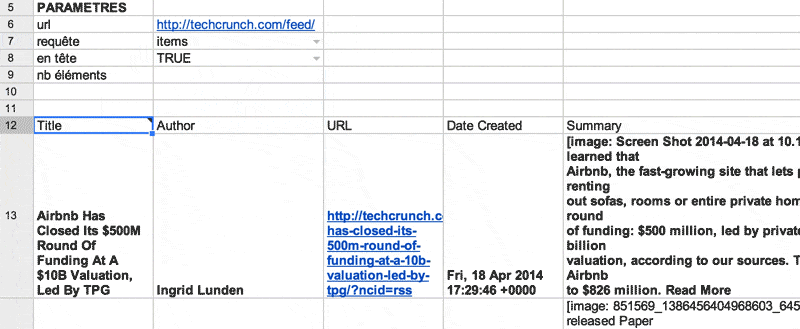
Créer un lecteur de flux RSS dans Google spreadhseet
Exemple d’utilisation:
IMPORTHTML("http://fr.wikipedia.org/wiki/Parts_de_marché_des_navigateurs_web","table",1)
[zilla_button url= »#exemples » style= »blue » size= »medium » type= »round » target= »_self »] Essayez par vous même ! [/zilla_button]
Pour plus d’information, reportez vous à la documentation Google Spreadsheet ImportFeed.
Traduire ses flux RSS dans Google spreadhseet
Bonus, parce que lire ses flux dans Google Spreadsheet, ça ne sert pas à grand chose seul…par contre, une fois qu’on les a dans la feuille de calcul, on peut les traduire facilement: il suffit de créer un nouvel onglet et d’utiliser la fonction « Translate » inclus dans google spreadsheet 
Exemple d’utilisation:
=GoogleTranslate("Il fait chaud et beau";"fr"; "en")

Voila. Simplissime..
ImportXml: importer à peu près n’importe quoi dans google spreadsheet
La fonction ImportXml est la plus puissante: elle permet d’extraire absolument n’importe quoi d’une page web. Par contre, elle va demander de plus grande compétences techniques. Pas besoin de savoir développer, mais il va connaitre la notion de Xpath, et comment déterminer celui de l’élément à extraire de la page web.
Avec la fonction ImportXML, la seule limitation (à ma connaissance) est liée à l’execution de javascripts sur la page: vous ne pourrez extraire des données que si elles sont affichées dans la page avant l’execution de javascript. Ce n’est pas un problème pour la plupart des sites internet, mais dans certains cas, mais pourra l’être si par exemple vous cherchez à extraire une donnée qui nécessite un clic sur un bouton pour être affichée, etc.
Utilisation de la fonction ImportXml de Google Spreadsheet
Syntaxe:
=IMPORTXML(url, xpath)

- url: l’adresse de la page d’où extraire les données (avec le http)
- xpath: le xpath de/des éléments à extraire de la page.
NB: Il est possible d’extraire plusieurs xpath en une seule requête en les séparant par des « pipes » (|). Par exemple:
=IMPORTXML("http://www.twitter.com/search?q=growth hacking"; "user xpath | twitter account xpath")
A priori, rien de très compliqué, mais récupérer le xpath peut parfois être un casse tête…
Qu’est ce qu’un Xpath ?
C’est la partie la plus difficile à maitriser concernant cette fonction. Si vous prenez le temps de bien comprendre comment les construire par contre, vous aurez un outils extrêmement puissant…
Récupérer le xpath d’un élément isolé d’une page est relativement facile, je vous explique juste en dessous. Par contre, pour récupérer une liste d’éléments (résultats de recherche, etc.), vous devrez forcément le modifier « à la main » et donc comprendre comment les construire. Pour commencer, l’article Xpath sur Wikipedia est une excellente 1ère approche.
En résumé, le Xpath est le chemin unique d’un élément dans un document formatté (xml, html…). Par exemple, dans le code suivant:
Brice Maurin
@deuxio
http://deux.io
Antoine Richard
@doublesensparis
http://www.doublesens.fr
Pierre le Ny
@labelgum
http://www.label-gum.com
Pour récupérer dans un tableau les nom, twitter id & site web de la liste, je pourrais utiliser les fonctions suivante:
=IMPORTXML("http://www.domaine.com/nomdelapage"; "//*[@id='name']")
=IMPORTXML("http://www.domaine.com/nomdelapage"; "//*[@id='twitter-id']")
=IMPORTXML("http://www.domaine.com/nomdelapage"; "//*[@id='website']")
ou en récupérant tout en 1 fois (dans une seule colonne par contre…) grace à la fonction suivante:
=IMPORTXML("http://www.domaine.com/nomdelapage"; "//*[@id='name'] | //*[@id='twitter-id'] | //*[@id='website']")
Passons sur le nom de la page. Le paramètre xPath passé est ici composé de 3 xPath différents, séparés par des « pipes » ( | ou Alt+Shit+L sur mac) pour indiquer à google spreadsheet que je souhaite récupérer plusieurs champs en 1 seul appel à la fonction importxml.
Je récupère donc le nom en recherchant partout dans le document (//) le champs dont l’id est « name » ([@id= »name »]). De la même manière, je lui indique les 2 autres champs qu’il doit aller récupérer (//[@id=’twitter-id’] et //*[@id=’website’]).
NB: Lorsque vous souhaitez extraire des id ou des class en les nommant, pensez à les inclure avec des single quotes, pour éviter d’indiquer (avec des doubles) la fin de la fonction à google spreadsheet.
Récupérer le Xpath d’un élément d’une page web directement dans Chrome
Sélectionnez l’élément à extraire dans la page, puis faites un clic droit. Choisissez « Procéder à l’inspection de l’élément ». Les outils de développement Chrome vont s’afficher, en surlignant dans le code la ligne que vous avez sélectionné. Faites un clic droit (dans le code), sur cet élément et choisissez « Copy Xpath »:
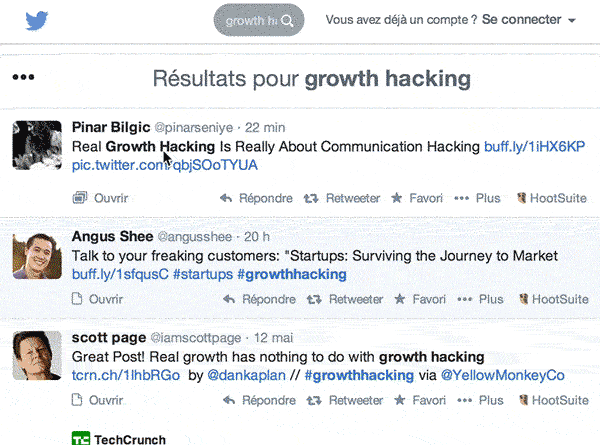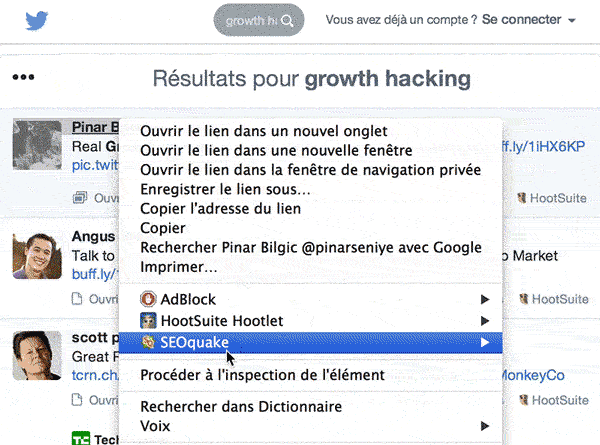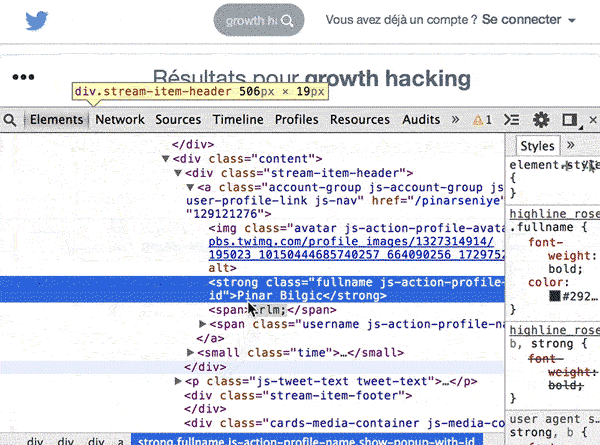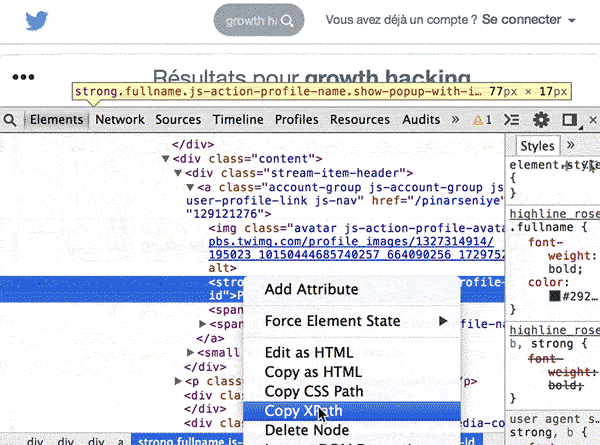
Coller ce Xpath dans votre formule, et Google extraira l’élément de la page dans la feuille de calcul.
Quelques exemples de xPath bien pratiques 
Tous les exemples sont contenus dans le Google Spreadsheet contenant les exemples mentionnés dans ce tutoriel.
Récupérer les titres & urls des résultats de recherche de google
Exemple de recherche sur Google: https://www.google.fr/search?q=growth+hacking
Titre de la page: //h3[@class=’r’]
Url de la page: //h3[@class=’r’]/a/@href
Exemple d’utilisation de la fonction ImportXml pour extraire des données depuis une recherche Google
Dans la 1ère colonne, entrez la formule suivante permettant de récupérer le titre des pages de résultat:
=IMPORTXML("https://www.google.fr/search?pws=0&q=growth hacking"; "//h3[@class='r']")
Le début de l’url google est standard, mais j’y ai ajouté le paramètre « pws=0 » qui permet de faire une recherche non personnalisée, c’est à dire une recherche qui ne prend pas en compte vos recherches précédentes & vos paramètres google personnels.
Dans la colonne suivante, entrez la formule suivante permettant de récupérer les urls des pages de résultat:
=IMPORTXML("https://www.google.fr/search?pws=0&q=growth hacking"; "//h3[@class='r']/a/@href")
Vous remarquerez que google ne retourne pas directement les urls des pages de résultats, mais une adresse lui permettant de tracker tous les clics sur les liens. L’url ressemble à ça:
/url?q={url de la page}&sa={un code qui rend le clic unique, et donc reliable à une personne unique}
Pour obtenir l’url « propre », nous allons l’extraire à l’aide de la fonction « RegExExtract ». Entrez donc dans la 3e colonne la formule suivante:
=REGEXEXTRACT({cellule contenant l'url encryptée};"/url?q=(.+)&sa")
Vous obtiendrez une belle url, bien propre et non suivie
[zilla_button url= »#exemples » style= »blue » size= »medium » type= »round » target= »_self »] Essayez par vous même ! [/zilla_button]
Récupérer les noms d’utilisateurs / url du tweet d’une recherche twitter
Exemple de recherche sur Twitter: https://twitter.com/search?q=growth hacking&mode=news (le &mode=news sert à n’afficher que les news, pas les recommandations de users)
Nom d’utilisateur: //[contains(@class, ‘fullname’)]
Compte Twitter: //[contains(@class, ‘username’)]/b
Url du Tweet: //*[contains(@class, ‘details’)]/@href
Exemple d’utilisation de la fonction importxml pour extraire des données depuis une recherche twitter
Dans 3 colonnes, copiez les 3 formules suivantes:
=IMPORTXML("https://twitter.com/search?q=growth hacking&mode=news"; "//*[contains(@class, 'fullname')]")
=IMPORTXML("https://twitter.com/search?q=growth hacking&mode=news"; "//*[contains(@class, 'username')]/b")
=IMPORTXML("https://twitter.com/search?q=growth hacking&mode=news"; "//*[contains(@class, 'details')]/@href")
Ce qui nous donne un tableau comme celui ci:
[zilla_button url= »#exemples » style= »blue » size= »medium » type= »round » target= »_self »] Essayez par vous même ! [/zilla_button]
Exemples mentionnés dans ce tutorial
Testez par vous même les fonctions importXml, importHtml, importFeed de google spreadsheet grâce à notre feuille de calcul.
Vous y trouverez les exemples suivants:
- importHtml: Extraire un tableau d’une page wikipedia
- importHtml: Extraire le calendrier des séries de la semaine
- importFeed: Créer un lecteur de flux RSS dans Google spreadhseet
- importFeed + Googletranslate: Traduire ses flux RSS dans Google spreadhseet
- importXml: faire une recherche GOOGLE depuis Google spreadsheet
- importXml: faire une recherche TWITTER depuis Google spreadsheet
Feuille de calcul « IMPORTXML »
Feuille de calcul « IMPORTFEED »Pour les modifier, choisissez « Fichier » > « Créer une Copie ».N’hésitez pas à posez vos questions en commentaires
Les limitations des fonctions import de google spreadsheet
La limitation la plus importante est que l’on ne peut pas utiliser plus de 50 fonctions import(Xml/Html/Feed) par feuille de calcul. Pour passer outre cette limitation, 2 solutions:
- utiliser des « pipes » (|) entre les xpath pour grouper plusieurs importXml en 1 seul appel
- utiliser plusieurs feuilles de calcul

- utiliser cette méthode mentionnée sur quora
[EDIT: Janvier 2015] C’est fini ! Google vient de lever sa limitation On peut maintenant scraper en illimité !! Yeah !










Commentaires
Enregistrer un commentaire
🖐 Hello,
N'hésitez pas à commenter ou vous exprimer si vous avez des trucs à dire . . .👉