Reconnaissance vocale Python avec SpeechRecognition - PythonAlgos
Référence
Avancé
JeuUn moteur de jeu avec une LED unique.imagesCréation, manipulation et affichage d'images LED.épinglesContrôlez le courant des broches pour les signaux analogiques/numériques, les servos, i2c.en sérieLire et écrire des données sur une connexion série.contrôlerUtilitaires d'exécution et d'événements.
Bluetooth
Voir aussi
Créez votre propre résumé de texte AI en Python

Pour cet exemple, nous allons construire un résumé de texte extractif naïf en 25 lignes de Python. Un résumé extractif est un résumé d'un document directement extrait du texte. Pour plus d'informations sur les résumés IA, consultez cet article sur Qu'est-ce que le résumé de texte IA et comment puis-je l'utiliser ?
Nous allons construire un résumé de texte IA de deux manières. D'abord avec spaCy , puis avec The Text API . spaCy est l'une des bibliothèques Python open source pour le traitement du langage naturel. L'API Text est la meilleure API complète d'analyse des sentiments en ligne.
Dans cet article sur la création d'un AI Text Summarizer en Python, nous aborderons :
- Construire un résumé de texte AI en moins de 30 lignes de Python
- Obtenir le nombre de chaque mot dans le texte
- Notation des phrases pour le résumé de texte
- Trier les phrases pour notre résumé de texte AI
- Retour du résumé de texte
- Construire un résumé de texte AI en moins de 15 lignes de Python
- Configuration de la demande d'API à l'AI Text Summarizer
- Analyse de la réponse AI Text Summarizer
Construire un résumé de texte AI en moins de 30 lignes de Python
Avant de pouvoir commencer avec le code, nous devons installer spaCy et télécharger un modèle. Nous pouvons le faire dans le terminal avec les deux commandes suivantes. Le en_core_web_smmodèle est le plus petit modèle et le plus rapide pour démarrer. Vous pouvez également télécharger en_core_web_md, en_core_web_lg, et en_core_web_trfpour d'autres modèles plus grands en anglais.
configuration requise pour la bibliothèque de résumés de textepip install spacy python -m spacy download en_core_web_sm
Commençons par le code de notre synthétiseur de texte ! Tout d'abord, nous allons importer spacyet charger le modèle de langage que nous avons téléchargé précédemment.
importer la bibliothèque et le modèle de synthèse de texteimport spacy nlp = spacy.load("en_core_web_sm")
Pour ce didacticiel, nous allons créer un résumé de texte extractif simple basé uniquement sur les mots du texte et la fréquence à laquelle ils sont mentionnés. Nous allons décomposer ce résumé de texte en quelques étapes simples.
Nous allons d'abord créer un dictionnaire de mots pour suivre le nombre de mots. Ensuite, nous allons noter chaque phrase en fonction de la fréquence à laquelle chaque mot de cette phrase apparaît. Après cela, nous allons trier les phrases en fonction de leur score. Enfin, nous prendrons les trois phrases les mieux notées et les renverrons dans le même ordre qu'elles apparaissaient à l'origine dans le texte.
Avant d'aborder tout cela, chargeons notre texte et transformons-le en un SpaCy Document . Vous pouvez utiliser le texte que vous voulez. Le texte fourni n'est qu'un exemple qui parle de moi et de ce blog.
résumé de texte - exemple de texte# extractive summary by word count text = """This is an example text. We will use seven sentences and we will return 3. This blog is written by Yujian Tang. Yujian is the best software content creator. This is a software content blog focused on Python, your software career, and Machine Learning. Yujian's favorite ML subcategory is Natural Language Processing. This is the end of our example.""" # tokenize doc = nlp(text)
Obtenir que tous les mots comptent
Maintenant que nous avons notre texte sous forme de Doc, nous pouvons obtenir tous nos comptes de mots. Vous pouvez en fait le faire avant en divisant la chaîne sur les espaces, mais c'est plus facile et nous aurons de toute façon besoin du Doc plus tard.
Commençons par créer un dictionnaire de mots. Ensuite, nous allons parcourir le texte et vérifier si chaque mot se trouve dans le dictionnaire. Si le mot est dans le dictionnaire, nous incrémenterons son compteur, sinon nous mettrons son compteur à un. Nous enregistrerons chaque mot en format minuscule.
créer un dictionnaire de mots pour le résumé de texte ai# create dictionary word_dict = {} # loop through every sentence and give it a weight for word in doc: word = word.text.lower() if word in word_dict: word_dict[word] += 1 else: word_dict[word] = 1
Notation des phrases pour notre résumé de texte AI
Une fois que nous avons rassemblé tous les mots, nous pouvons les utiliser pour marquer nos phrases. Nous allons créer une liste de tuples. Chaque tuple contient des informations dont nous avons besoin sur la phrase - le texte de la phrase, le score de la phrase et l'index de la phrase d'origine. Nous allons parcourir chaque index et chaque phrase dans les phrases Doc énumérées.
La enumeratecommande renvoie un index et l'élément à cet index pour tout itérable. Pour chaque mot de la phrase, nous ajouterons le score du mot au score de la phrase. À la fin de la boucle sur tous les mots de la phrase, nous ajoutons le texte de la phrase, le score de la phrase normalisé par la longueur et l'index d'origine.
notez chaque phrase pour le résumé de texte# create a list of tuple (sentence text, score, index) sents = [] # score sentences sent_score = 0 for index, sent in enumerate(doc.sents): for word in sent: word = word.text.lower() sent_score += word_dict[word] sents.append((sent.text.replace("\n", " "), sent_score/len(sent), index))
Tri des phrases pour le récapitulatif de texte
Maintenant que notre liste de phrases est créée, nous allons devoir les trier afin d'obtenir les phrases les mieux notées dans notre résumé. Nous allons d'abord utiliser une fonction lambda pour trier par la version négative du score.
Pourquoi négatif ? Parce que la fonction de tri automatique trie du plus petit au plus grand. Après avoir trié par score, nous prenons les 3 premiers, puis nous les trions à nouveau par index afin que notre résumé soit dans l'ordre. Vous pouvez prendre autant de phrases que vous le souhaitez et même modifier le nombre de phrases que vous souhaitez en fonction de la longueur du texte.
trouver les phrases les plus importantes pour le résumé de texte# sort sentence by word occurrences sents = sorted(sents, key=lambda x: -x[1]) # return top 3 sents = sorted(sents[:3], key=lambda x: x[2])
Renvoi du résumé
Tout ce que nous avons à faire pour obtenir notre résumé résultant est de prendre la liste des phrases triées et de les assembler, séparées par un espace. Enfin, nous l'imprimerons pour jeter un coup d'œil.
python de synthèse de texte# compile them into text summary_text = "" for sent in sents: summary_text += sent[0] + " " print(summary_text)
Une fois que nous avons exécuté notre programme, nous devrions voir un exemple comme celui ci-dessous. C'est tout ce qu'il y a à faire pour créer un résumé de texte simple en Python avec spaCy !

Construire un résumé de texte AI en 15 lignes de Python
Nous avons donc expliqué comment créer un résumé de texte AI en moins de 30 lignes de code, faisons-le également en 15. Pour cette partie du didacticiel, nous n'avons qu'à envoyer une requête HTTP. Avant de commencer, nous devrons nous rendre sur l'API Text et nous inscrire pour obtenir une clé API gratuite. Une fois que vous vous êtes enregistré pour une clé, vous devrez installer la requestsbibliothèque.
synthétiseur de texte ai – bibliothèque de requêtespip install requests
Nous allons importer les bibliothèques dont nous avons besoin pour commencer. Nous utiliserons requestspour envoyer notre requête HTTP et jsonpour analyser la réponse.
importations de résumés de texte aiimport requests import json from config import apikey
Configuration de la requête API
Configurons la requête. Le texte que nous allons résumer est une description de l'API Text et de ce qu'elle peut faire. Nous devrons également configurer des en-têtes, le corps et le point de terminaison de l'URL. Les en-têtes indiqueront au serveur que le contenu que nous envoyons est au format JSON et transmettront également la clé API que nous avons obtenue précédemment. Le corps passera simplement le texte que nous avons comme attribut "texte". L'URL sera le summarizepoint de terminaison de l'API Text.
éléments de demande de résumé de texte aitext = "The Text API is easy to use and useful for anyone who needs to do text processing. It's the best Text Processing web API. The Text API allows you to do amazing NLP without having to download or manage any models. The Text API provides many NLP capabilities. These capabilities range from custom Named Entity Recognition (NER) to Summarization to extracting the Most Common Phrases. NER and Summarizations are both commonly used endpoints with business use cases. Use cases include identifying entities in articles, summarizing news articles, and more. The Text API is built on a transformer model." headers = { "Content-Type": "application/json", "apikey": apikey } body = { "text": text } url = "https://app.thetextapi.com/text/summarize"
Analyse de la réponse AI Text Summarizer
Après avoir configuré la requête, tout ce que nous avons à faire est d'envoyer la requête, puis d'analyser notre réponse via JSON. La requête renverra à la fois un userélément et un summaryélément. Nous avons seulement besoin de la valeur de l' summaryarticle.
analyser la réponse du résumé de texteresponse = requests.post(url, headers=headers, json=body) summary = json.loads(response.text)["summary"] print(summary)
Exécutons ceci et voyons notre réponse. Cela devrait ressembler à la réponse ci-dessous.

Vous pouvez en savoir plus sur d'autres concepts NLP tels que la reconnaissance d'entité nommée (NER) , le balisage de la partie du discours (POS) , et plus encore sur ce blog .
Lectures complémentaires
- Floyd Warshall en Python
- Pourquoi la programmation est facile mais le génie logiciel est difficile
- Listes imbriquées en Python
- Algorithme de Dijkstra en Python
- Comment exécuter des fonctions en parallèle en Python
Apprendre encore plus
Pour en savoir plus, n'hésitez pas à me contacter @yujian_tang sur Twitter, connectez-vous avec moi sur LinkedIn et rejoignez notre Discord . N'oubliez pas de suivre le blog pour rester à jour avec des projets Python sympas et des moyens d'améliorer vos compétences en logiciel et Python ! Si vous avez aimé cet article, merci de le tweeter, de le partager sur LinkedIn ou de le dire à vos amis !
Reconnaissance vocale Python avec SpeechRecognition

Reconnaissance vocale avec SpeechRecognition ? Ouais. SpeechRecognition est une bibliothèque de reconnaissance vocale automatique (ASR) pour Python. SpeechRecognition est une bibliothèque wrapper qui fonctionne avec plusieurs backends, notamment CMU Sphinx, Google Cloud et Azure. Trouvez le code que nous couvrons ci-dessous dans le Github officiel de reconnaissance vocale Python .
Dans cet article, nous verrons comment utiliser la bibliothèque Python SpeechRecognition avec plusieurs backends. Nous couvrirons :
- Qu'est-ce que la bibliothèque Python SpeechRecognition ?
- Premiers pas avec la reconnaissance vocale Python
- Prérequis pour la reconnaissance vocale Python
- Reconnaissance vocale Python via CMU Sphinx
- Reconnaissance vocale à l'aide de la reconnaissance vocale Google
- Google Cloud Speech to Text pour la reconnaissance vocale avec Python SpeechRecognition
- Reconnaissance vocale Python avec Wit.AI
- Microsoft Azure Speech to Text pour la reconnaissance vocale Python
- Microsoft Bing Voice Recognition pour faire de la reconnaissance vocale en Python
- Reconnaissance vocale Python avec Houndify
- IBM Speech to Text dans Python SpeechRecognition
- Reconnaissance vocale Python avec d'autres bibliothèques
- Résumé de la reconnaissance vocale Python avec la bibliothèque SpeechRecognition
Qu'est-ce que la bibliothèque Python SpeechRecognition ?
Python SpeechRecognition est un projet sous licence BSD 3-Clause de 2014 à 2017 par Anthony Zhang. C'est un wrapper qui se connecte à plusieurs API et moteurs. La bibliothèque SpeechRecognition est annoncée pour prendre en charge CMU Sphinx, Google Speech Recognition, Google Cloud Speech API, Wit.ai, Microsoft Bing Voice Recognition, Houndify API, IBM Speech to Text et Snowboy Hotword Detection.
Notez que Snowboy n'est plus là. Un inconvénient de SpeechRecognition est que cette bibliothèque de reconnaissance vocale Python manque de puissants backends. Certains backends puissants actuels qui manquent incluent PyTorch, Tensorflow et des API Web plus récentes comme Deepgram .
Premiers pas avec la reconnaissance vocale Python
Prenons du recul par rapport au code et comprenons comment la reconnaissance vocale Python se produit à un niveau élevé. La reconnaissance vocale automatique peut être effectuée à la fois en temps réel en diffusant de l'audio et de manière asynchrone sur des fichiers audio. Dans cet article, nous allons expliquer comment utiliser SpeechRecognition pour exécuter la reconnaissance vocale asynchrone sur un fichier audio.
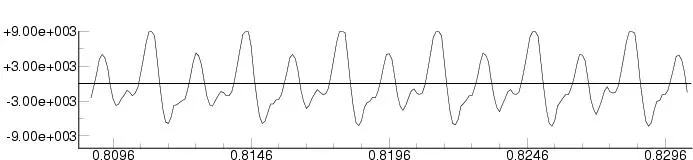
Nous commençons avec les données audio , qui ressemblent à une forme d'onde comme le montre l'image ci-dessus. Python convertit ces données de forme d'onde sous la forme d'un ensemble de nombres appelé vecteur. Nous combinons plusieurs vecteurs dans une matrice. Ces données au format vecteur/matrice sont ensuite introduites dans un réseau de neurones formé qui nous donne une prédiction.
Maintenant que nous comprenons comment fonctionne la reconnaissance vocale, entrons dans le code. La bibliothèque Python SpeechRecognition nous permet d'utiliser de nombreux modèles différents pour faire de la reconnaissance vocale. Chacune de ces sections couvre un modèle/moteur/backend différent qui effectue la reconnaissance vocale. Vous pouvez obtenir des résultats différents pour chaque application.
Prérequis pour la reconnaissance vocale Python
Tout d'abord, nous devons installer la bibliothèque Python SpeechRecognition. Nous pouvons le faire avec la ligne pip install SpeechRecognition. Une fois la bibliothèque installée, nous commençons. Tout le code ci-dessous appartient au même fichier.
La configuration commence par importer d'abord la speech_recognitionbibliothèque et le fichier os. Ensuite, nous utilisons la osbibliothèque pour trouver notre fichier audio. Dans cet exemple, il y a un fichier WAV anglais, un fichier AIFF français et un fichier FLAC chinois. Ensuite, nous devons instancier le système de reconnaissance vocale SpeechRecognition. À partir de là, nous ouvrons le fichier audio en tant que source et le lisons dans le système de reconnaissance vocale.
import speech_recognition as sr
# obtain path to "english.wav" in the same folder as this script
from os import path
AUDIO_FILE = path.join(path.dirname(path.realpath(__file__)), "english.wav")
# AUDIO_FILE = path.join(path.dirname(path.realpath(__file__)), "french.aiff")
# AUDIO_FILE = path.join(path.dirname(path.realpath(__file__)), "chinese.flac")
# use the audio file as the audio source
r = sr.Recognizer()
with sr.AudioFile(AUDIO_FILE) as source:
audio = r.record(source) # read the entire audio fileReconnaissance vocale Python via CMU Sphinx
Le premier backend que nous essayons pour cet exemple est CMU Sphinx. CMU Sphinx est un moteur de reconnaissance vocale automatique open source issu de l'Université Carnegie Mellon. CMU Sphinx a été en grande partie inactif au cours de la dernière décennie, mais la maintenance vient de redémarrer en 2022 !
Tout ce que nous avons à faire pour utiliser le backend CMU Sphinx avec Python SpeechRecognition est d'appeler la recognize_sphinx()fonction sur les données audio. Nous traitons deux erreurs différentes, les erreurs de valeur inconnue et les erreurs de requête.
# recognize speech using Sphinx
try:
print("Sphinx thinks you said " + r.recognize_sphinx(audio))
except sr.UnknownValueError:
print("Sphinx could not understand audio")
except sr.RequestError as e:
print("Sphinx error; {0}".format(e))Reconnaissance vocale à l'aide de la reconnaissance vocale Google
Ensuite, nous verrons comment utiliser la reconnaissance vocale de Google. Cela utilise l'API de reconnaissance vocale Chrome. Ce service ne nécessite pas de compte Google Cloud Developer, mais peut être désactivé par Google à tout moment. Ce service fonctionnait lorsque ce code a été écrit, votre kilométrage peut varier.
Tout comme CMU Sphinx, la mise en œuvre est simple. Nous appelons simplement recognize_googleles données audio. Nous gérons également les deux mêmes types d'erreurs, une erreur de valeur inconnue et une erreur de requête.
# recognize speech using Google Speech Recognition
try:
# for testing purposes, we're just using the default API key
# to use another API key, use `r.recognize_google(audio, key="GOOGLE_SPEECH_RECOGNITION_API_KEY")`
# instead of `r.recognize_google(audio)`
print("Google Speech Recognition thinks you said " + r.recognize_google(audio))
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))Google Cloud Speech to Text pour la reconnaissance vocale avec Python SpeechRecognition
Cette section couvre l'utilisation de Google Cloud Speech to Text. Google Cloud Speech to Text est l'outil Google Cloud Platform qui effectue la reconnaissance vocale automatique. C'est un outil plug and play. Google propose des didacticiels sur l'utilisation de Google Cloud Speech to Text avec Go, Java, Python et Node JS.
Contrairement à l'option CMU Sphinx ci-dessus, Google Cloud Speech to Text nécessite des informations d'identification. Google Cloud Speech to Text fournit des informations d'identification sous la forme d'un fichier JSON. Lors de l'appel de la fonction pour cet outil, recognize_gooogle_cloudnous transmettons les données audio et les informations d'identification. Tout comme CMU Sphinx, nous gérons les deux mêmes erreurs, les valeurs inconnues et les erreurs de requête.
# recognize speech using Google Cloud Speech
GOOGLE_CLOUD_SPEECH_CREDENTIALS = r"""INSERT THE CONTENTS OF THE GOOGLE CLOUD SPEECH JSON CREDENTIALS FILE HERE"""
try:
print("Google Cloud Speech thinks you said " + r.recognize_google_cloud(audio, credentials_json=GOOGLE_CLOUD_SPEECH_CREDENTIALS))
except sr.UnknownValueError:
print("Google Cloud Speech could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Cloud Speech service; {0}".format(e))Reconnaissance vocale Python avec Wit.AI
Wit AI est un outil de reconnaissance vocale acquis par Facebook (Meta) en 2015. Ils n'ont pas beaucoup d'informations sur leur blog sur qui ils sont ou ce qu'ils font. Heureusement, nous pouvons nous interfacer avec Python SpeechRecognition pour l'utiliser. Tout comme Google Cloud Speech to Text, Wit AI fonctionne avec une clé API. La clé API de Wit est une chaîne alphanumérique majuscule de 32 caractères.
Comme tous les autres exemples ci-dessus, SpeechRecognition fournit une fonction intégrée pour Wit AI. Tout ce que nous faisons est d'appeler recognize_witavec les données audio et de transmettre la clé API Wit AI dans le keyparamètre. Comme toutes les options ci-dessus, nous gérons les deux mêmes erreurs.
# recognize speech using Wit.ai
WIT_AI_KEY = "INSERT WIT.AI API KEY HERE" # Wit.ai keys are 32-character uppercase alphanumeric strings
try:
print("Wit.ai thinks you said " + r.recognize_wit(audio, key=WIT_AI_KEY))
except sr.UnknownValueError:
print("Wit.ai could not understand audio")
except sr.RequestError as e:
print("Could not request results from Wit.ai service; {0}".format(e))Microsoft Azure Speech to Text pour la reconnaissance vocale Python
Microsoft Azure Speech to Text est la version Microsoft de Google Cloud Speech to Text. La clé API pour Azure Speech to Text est une chaîne hexadécimale minuscule de 32 caractères. La même longueur que Wit mais un contenu légèrement différent. Beaucoup plus court que le fichier JSON utilisé par Google Cloud Speech to Text.
La bibliothèque Python Speech Recognition facilite énormément l'appel de l'un de ces backends. Dans ce cas, nous appelons recognize_azureet transmettons les données audio et la clé API Azure Speech to Text. Tout comme CMU Sphinx et Google Cloud Speech to Text, nous gérons les valeurs inconnues et les erreurs de requête.
# recognize speech using Microsoft Azure Speech
AZURE_SPEECH_KEY = "INSERT AZURE SPEECH API KEY HERE" # Microsoft Speech API keys 32-character lowercase hexadecimal strings
try:
print("Microsoft Azure Speech thinks you said " + r.recognize_azure(audio, key=AZURE_SPEECH_KEY))
except sr.UnknownValueError:
print("Microsoft Azure Speech could not understand audio")
except sr.RequestError as e:
print("Could not request results from Microsoft Azure Speech service; {0}".format(e))Microsoft Bing Voice Recognition pour faire de la reconnaissance vocale en Python
Pourquoi Microsoft propose-t-il deux outils de reconnaissance vocale différents ? En raison d'un dysfonctionnement de l'entreprise. Microsoft Bing Voice Recognition est un autre outil de reconnaissance vocale de Microsoft. Il n'était peut-être pas sur Azure au moment de la rédaction de ce code, mais il l'est certainement maintenant.
Bing utilise une clé API au même format que la clé API Azure. Vous fait vraiment réfléchir, pourquoi ces deux-là sont-ils différents? Quoi qu'il en soit, nous faisons appel recognize_bingaux données audio avec la clé API Bing pour obtenir notre transcription. Comme tous les autres backends ci-dessus, nous gérons les deux mêmes erreurs.
# recognize speech using Microsoft Bing Voice Recognition
BING_KEY = "INSERT BING API KEY HERE" # Microsoft Bing Voice Recognition API keys 32-character lowercase hexadecimal strings
try:
print("Microsoft Bing Voice Recognition thinks you said " + r.recognize_bing(audio, key=BING_KEY))
except sr.UnknownValueError:
print("Microsoft Bing Voice Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Microsoft Bing Voice Recognition service; {0}".format(e))Reconnaissance vocale Python avec Houndify
Houndify est une plateforme d'IA vocale de SoundHound. Ils offrent plus qu'une simple reconnaissance vocale automatique. Houndify fournit également une compréhension du langage naturel et des capacités de synthèse vocale. Contrairement aux outils de reconnaissance vocale Azure et Google Cloud, Houndify utilise deux clés API.
Houndify nécessite un identifiant et une clé. Ces deux chaînes sont codées en base 64. L'utilisation de la reconnaissance vocale de Houndify avec Python SpeechRecognition est aussi simple que les autres moteurs. Nous appelons recognize_houndifyet transmettons les données audio, l'ID et la clé.
# recognize speech using Houndify
HOUNDIFY_CLIENT_ID = "INSERT HOUNDIFY CLIENT ID HERE" # Houndify client IDs are Base64-encoded strings
HOUNDIFY_CLIENT_KEY = "INSERT HOUNDIFY CLIENT KEY HERE" # Houndify client keys are Base64-encoded strings
try:
print("Houndify thinks you said " + r.recognize_houndify(audio, client_id=HOUNDIFY_CLIENT_ID, client_key=HOUNDIFY_CLIENT_KEY))
except sr.UnknownValueError:
print("Houndify could not understand audio")
except sr.RequestError as e:
print("Could not request results from Houndify service; {0}".format(e))IBM Speech to Text dans Python SpeechRecognition
Le dernier backend Python SpeechRecognition que nous allons couvrir dans cet article est IBM Speech to Text . Il s'agit du concurrent d'IBM à Google Cloud et Azure speech to text. Il est construit à partir de la légendaire Watson AI d'IBM. L'interface API est légèrement différente en ce sens qu'elle utilise un nom d'utilisateur et un mot de passe. Le nom d'utilisateur n'est pas dans un format facile, ce qui n'est pas bon.
Vous savez déjà que SpeechRecognition fournit une fonction pour appeler ce moteur. Nous appelons la recognize_ibmfonction. Nous lui transmettons les données audio, le nom d'utilisateur et le mot de passe. Tout comme nous l'avons fait ci-dessus, nous gérons également les deux mêmes types d'erreurs : les valeurs inconnues et les erreurs de requête.
IBM_USERNAME = "INSERT IBM SPEECH TO TEXT USERNAME HERE" # IBM Speech to Text usernames are strings of the form XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
IBM_PASSWORD = "INSERT IBM SPEECH TO TEXT PASSWORD HERE" # IBM Speech to Text passwords are mixed-case alphanumeric strings
try:
print("IBM Speech to Text thinks you said " + r.recognize_ibm(audio, username=IBM_USERNAME, password=IBM_PASSWORD))
except sr.UnknownValueError:
print("IBM Speech to Text could not understand audio")
except sr.RequestError as e:
print("Could not request results from IBM Speech to Text service; {0}".format(e))Reconnaissance vocale Python avec d'autres bibliothèques
Python SpeechRecognition a été créé au milieu des années 2010. Bien qu'il soit toujours utile et pertinent, il lui manque quelques puissantes bibliothèques modernes. Depuis la fin des années 2010, nous avons vu la montée en puissance de PyTorch et TensorFlow dans l'apprentissage automatique. Maintenant, nous avons des bibliothèques comme PyTorch TorchAudio qui peuvent manipuler des données audio et nous aider à faire de la reconnaissance vocale.
D'autres bibliothèques de reconnaissance vocale en Python incluent DeepSpeech, Kaldi et wav2vec. DeepSpeech est issu d'un article de Baidu de 2014. Kaldi a commencé en 2009 à Johns Hopkins. Facebook a annoncé wav2vec comme outil ASR en 2019. Nous avons également vu la montée en puissance de sociétés ASR comme AssemblyAI, Deepgram et Rev AI.
Résumé de la reconnaissance vocale Python avec la bibliothèque SpeechRecognition
Cet article sert d'introduction à la reconnaissance vocale Python. Nous expliquons comment utiliser la bibliothèque Python SpeechRecognition pour interagir avec plusieurs backends. Pour faire une reconnaissance vocale plus avancée, nous pouvons interagir directement avec ces backends ou en utiliser certains non inclus.
Les backends avec lesquels nous avons interagi sont : CMU Sphinx, Google Cloud Speech to Text, Microsoft Azure/Bing Speech to Text, Houndify, Wit AI et IBM Speech to Text. Nous avons également mentionné que nous pouvons faire de l'ASR avec des bibliothèques d'apprentissage automatique comme TensorFlow et PyTorch ainsi que des API Web.
Lectures complémentaires
- Créez votre propre résumé de texte AI en Python
- La meilleure façon de faire la reconnaissance d'entité nommée (NER) en Python
- Traitement automatique du langage naturel : qu'est-ce que la polarité du texte ?
- Construire un GRU RNN en Keras Python
- Analyse des sentiments de texte en Python
Apprendre encore plus
Pour en savoir plus, n'hésitez pas à me contacter @yujian_tang sur Twitter, connectez-vous avec moi sur LinkedIn et rejoignez notre Discord . N'oubliez pas de suivre le blog pour rester à jour avec des projets Python sympas et des moyens d'améliorer vos compétences en logiciel et Python ! Si vous avez aimé cet article, merci de le tweeter, de le partager sur LinkedIn ou de le dire à vos amis !
Je gère ce site pour vous aider, vous et d'autres comme vous, à trouver des projets sympas et à mettre en pratique des compétences logicielles. Si cela vous est utile et que vous appréciez votre site sans publicité, veuillez aider à financer ce site en faisant un don ci-dessous ! Si vous ne pouvez pas faire un don maintenant, pensez à nous la prochaine fois.
Analyse des sentiments textuels et comment le faire

L'analyse des sentiments est un exemple de traitement appliqué du langage naturel (TLN). Dans ce contexte, le « sentiment » est presque interchangeable avec la polarité du texte . La polarité du texte est une mesure de -1 à 1 du sentiment du texte. La définition du dictionnaire du sentiment est en fait « son point de vue ou son attitude envers quelque chose », cela peut donc inclure des émotions allant de la tristesse au bonheur en passant par la surprise. Bien qu'il soit possible de prédire l'émotion, cet article va se concentrer sur le caractère positif ou négatif d'un texte. Nous couvrirons les émotions dans un article sur la détection des émotions et comment le faire.
Dans cet article, nous couvrirons :
- Qu'est-ce que le sentiment textuel
- Sentiment du texte vs polarité du texte vs analyse du sentiment
- Comment utiliser l'IA pour obtenir un sentiment de texte
- Sentiment de texte IA avec spaCy
- Analyse des sentiments avec NLTK
- Comment obtenir le sentiment d'un texte avec une API Web
- Applications de l'analyse des sentiments textuels
- Titres COVID
- Résumé de Comment faire une analyse des sentiments avec l'IA
Qu'est-ce que le sentiment textuel ?
Voyons d'abord ce qu'est le sentiment textuel. Le sentiment du texte est le sentiment général d'un texte. C'est la vue d'ensemble fournie par un document texte. Nous utilisons le sentiment du texte pour mesurer la polarité d'une valeur de -1 à 1. Pour nos moyens, le sentiment mesurera si un document texte est généralement positif ou négatif. Une mesure naïve du sentiment textuel prend simplement une moyenne du sentiment de chaque mot.
Nous mesurerons le sentiment total d'un texte comme une combinaison pondérée du sentiment de différents mots, expressions et phrases. Vous êtes libre de décider comment vous souhaitez peser chaque mot, expression ou phrase. Dans nos exemples d'implémentation, nous prendrons des sentiments automatiques avec spaCy et NLTK que vous pourrez extrapoler et ajuster. L'API de texte utilise un mélange propriétaire de sentiments à partir de mots, d'expressions et de phrases.
Sentiment du texte vs polarité du texte vs analyse du sentiment
Avant d'entrer dans quelques exemples d'implémentation, obtenons une image plus claire du sentiment. Il y a trois phrases qui sont utilisées à peu près de manière interchangeable dans l'espace PNL par la plupart des gens. Le sentiment de texte, la polarité du texte et l'analyse des sentiments ne sont distingués que lorsque vous avez des cas d'utilisation spécifiques ou que vous parlez avec des experts en PNL. Prenons les définitions.
- Sentiment du texte - la vue d'ensemble d'un texte, y compris la positivité, les perspectives et l'émotion
- Polarité du texte - une mesure de -1 à 1 de la polarisation (positive ou négative) d'un texte
- Analyse des sentiments - le processus de détermination du sentiment d'un document texte
Dans cet article, nous expliquons comment utiliser l'analyse des sentiments pour déterminer la polarité d'un texte.
Comment puis-je utiliser l'IA pour obtenir le sentiment d'un texte ?
Le traitement automatique du langage naturel est un sous-domaine de l'intelligence artificielle. La polarité est une technique courante pour de nombreux pipelines NLP. Dans cet article, nous expliquerons comment utiliser deux des plus grandes bibliothèques Python NLP et une API pour obtenir un sentiment de texte. Nous allons d'abord faire du sentiment textuel avec spaCy , puis NLTK , et enfin avec The Text API .
Sentiment de texte IA avec spaCy
Pour obtenir le sentiment d'un texte avec spaCy, nous devrons installer deux bibliothèques et télécharger un modèle. Nous pouvons le faire en utilisant les lignes ci-dessous dans le terminal.
pip install spacy spacytextblob
python -m spacy download en_core_web_smNous commencerons notre programme de la même manière que nous le faisons toujours, en gérant les importations. Nous allons importer la spacybibliothèque et la SpacyTextBlobclasse depuis le spacytextblobpackage. Ensuite, nous allons charger le modèle et ajouter le spacytextblobau pipeline NLP. Nous pouvons utiliser n'importe quel texte, pour cet exemple, nous utiliserons simplement une description textuelle de l'API Text. Ensuite, nous créerons un document à partir du texte en utilisant le modèle NLP. Enfin, nous imprimerons la polarité globale du texte à partir du modèle.
polarité du texte spacyimport spacy from spacytextblob.spacytextblob import SpacyTextBlob nlp = spacy.load("en_core_web_sm") nlp.add_pipe('spacytextblob') text = "The Text API is super easy to use and super useful for anyone who needs to do text processing. It's the best Text Processing web API and allows you to do amazing NLP without having to download or manage any models." doc = nlp(text) print(doc._.polarity)
Analyse des sentiments avec NLTK
Pour suivre cet exemple en utilisant la bibliothèque NLTK, nous devrons installer la bibliothèque NLTK et télécharger les trois de ses packages. Nous pouvons le faire avec les lignes ci-dessous dans le terminal.
pip install nltk
python
>>> import nltk
>>> nltk.download([“averaged_perceptron_tagger”, “punkt”, “vader_lexicon”])Comme toujours, nous commencerons notre programme par les importations. Nous devrons importer la SentimentIntensityAnalyzerclasse depuis le nltk.sentimentmodule. Ensuite, nous allons initialiser un objet de la SentimentIntensityAnalyzerclasse. Nous utiliserons ici le même texte que pour le modèle spaCy. Ensuite, nous allons récupérer le polarity_scorestexte de l' SentimentIntensityAnalyzerobjet et imprimer les scores.
Polarité du texte NLTKfrom nltk.sentiment import SentimentIntensityAnalyzer sia = SentimentIntensityAnalyzer() text = "The Text API is super easy to use and super useful for anyone who needs to do text processing. It's the best Text Processing web API and allows you to do amazing NLP without having to download or manage any models." scores = sia.polarity_scores(text) print(scores)
Comment obtenir le sentiment d'un texte avec une API NLP
Pour cet exemple, nous devrons installer la requestsbibliothèque et obtenir une clé API gratuite auprès de The Text API . Vous pouvez télécharger la bibliothèque avec la ligne ci-dessous dans le terminal.
pip install requestsComme toujours, nous allons commencer notre programme avec les importations, nous devons importer la requestsbibliothèque pour envoyer des requêtes et la jsonbibliothèque pour analyser la réponse. J'ai également importé la clé API de mon fichier de configuration, mais vous pouvez l'importer depuis l'endroit où vous l'avez enregistrée ou l'utiliser dans ce fichier. Nous utiliserons exactement le même texte qu'avec spaCy et NLTK.
Nous devons créer des en-têtes à envoyer avec la requête. Les en-têtes indiqueront au serveur que nous envoyons du contenu JSON et transmettront la clé API. Le corps passera simplement l'objet texte. Nous devons également connaître l'URL du point de terminaison de l'API. Tout ce que nous avons à faire est d'envoyer une requête POST et d'analyser la réponse dans un objet JSON. La polarité sera la clé de « polarité du texte » de l'objet renvoyé.
la polarité du texte de l'api du texteimport requests import json from config import apikey text = "The Text API is super easy to use and super useful for anyone who needs to do text processing. It's the best Text Processing web API and allows you to do amazing NLP without having to download or manage any models." headers = { "Content-Type": "application/json", "apikey": apikey } body = { "text": text } url = "https://app.thetextapi.com/text/text_polarity" response = requests.post(url, headers=headers, json=body) polarity = json.loads(response.text)["text polarity"] print(polarity)
Applications de l'analyse des sentiments textuels
L'analyse des sentiments pour le texte peut être appliquée de plusieurs façons. Nous pouvons l'utiliser pour avoir une idée de ce que les gens disent vraiment dans les avis, de ce que les clients pensent de notre produit ou même de ce que les employés pensent de l'entreprise. Nous pouvons également l'utiliser pour analyser les nouvelles et voir si elles sont positives ou négatives. Dans cette section, nous montrerons un exemple d'utilisation de l'analyse des sentiments textuels pour analyser les titres COVID au fil du temps.
Polarité du sentiment textuel des titres COVID
Une application de l'analyse des sentiments textuels consiste à analyser les actualités. Comme cela fait environ deux ans que la pandémie de COVID a commencé, l'analyse des gros titres de COVID pourrait être intéressante. J'ai décidé de faire une analyse des gros titres du NY Times sur le COVID au cours des deux dernières années. Qu'est-ce que j'ai appris ? Qu'ils étaient beaucoup plus négatifs à propos de COVID la première année qu'ils ne l'ont été cette année.
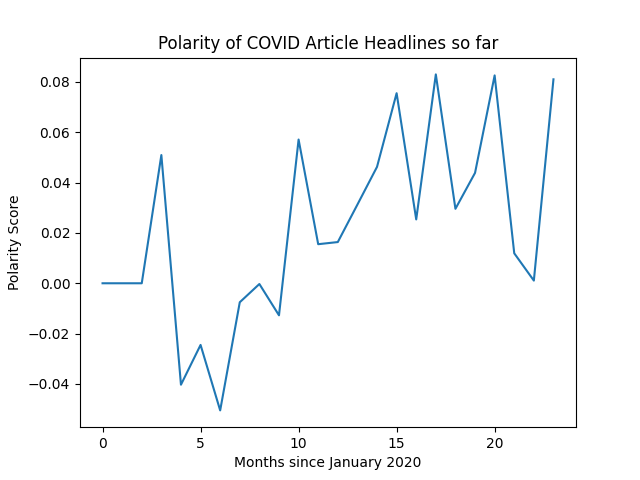
Pour un didacticiel complet, consultez Utilisation de l'IA pour analyser les titres COVID .
Résumé de Comment faire une analyse des sentiments avec l'IA
Dans cet article, nous avons découvert le sentiment textuel, l'analyse des sentiments et la polarité du texte. Nous avons appris que ces termes sont pour la plupart interchangeables mais présentent des différences nuancées. Ensuite, nous avons vu comment utiliser l'IA pour obtenir le sentiment d'un texte. Nous avons vu comment l'implémenter de trois manières différentes, avec spaCy, NLTK et The Text API. Enfin, nous avons vu un exemple de la façon dont nous pouvons appliquer l'analyse des sentiments textuels.
Apprendre encore plus
Pour en savoir plus, n'hésitez pas à me contacter @yujian_tang sur Twitter, connectez-vous avec moi sur LinkedIn et rejoignez notre Discord . N'oubliez pas de suivre le blog pour rester à jour avec des projets Python sympas et des moyens d'améliorer vos compétences en logiciel et Python ! Si vous avez aimé cet article, merci de le tweeter, de le partager sur LinkedIn ou de le dire à vos amis !
Je gère ce site pour vous aider, vous et d'autres comme vous, à trouver des projets sympas et à mettre en pratique des compétences logicielles. Si cela vous est utile et que vous appréciez votre site sans publicité, veuillez aider à financer ce site en faisant un don ci-dessous ! Si vous ne pouvez pas faire un don maintenant, pensez à nous la prochaine fois.









Commentaires
Enregistrer un commentaire
🖐 Hello,
N'hésitez pas à commenter ou vous exprimer si vous avez des trucs à dire . . .👉